
Google เปิดตัว ‘Gemma 4’ AI Open Model ที่ทรงพลังที่สุด รองรับ 140 ภาษา รันได้บนมือถือ Android ยันเซิร์ฟเวอร์ระดับองค์กร
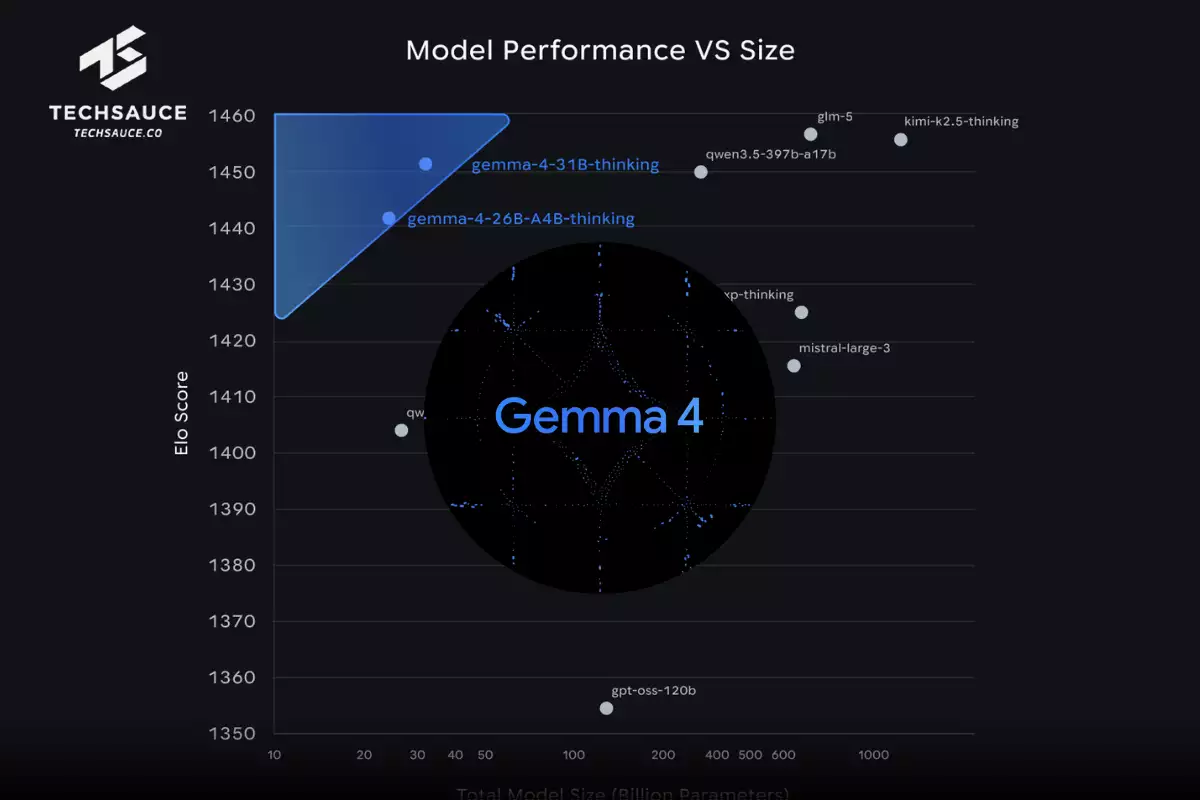
Google ประกาศเปิดตัว Gemma 4 ตระกูลโมเดล AI แบบเปิดที่บริษัทเรียกว่า 'ฉลาดที่สุด' เท่าที่เคยปล่อยออกมา โดยออกแบบมาเพื่อรองรับงานการใช้เหตุผลขั้นสูงและระบบการทำงานแบบเอเจนต์โดยเฉพาะ พร้อมจุดขายสำคัญคือสามารถรันได้บนฮาร์ดแวร์หลากหลายระดับ ตั้งแต่สมาร์ทโฟน Android ไปจนถึง GPU ระดับศูนย์ข้อมูล
ออกแบบมาให้รันได้ทุกที่ ไม่ใช่แค่บนคลาวด์
สิ่งที่ทำให้ Gemma 4 แตกต่างจากโมเดลขนาดใหญ่ของค่ายอื่นคือแนวคิดเรื่อง 'การเข้าถึงได้ง่าย' Google ปรับขนาดโมเดลให้สามารถรันและปรับแต่งได้อย่างมีประสิทธิภาพบนฮาร์ดแวร์ที่หลากหลาย ตั้งแต่อุปกรณ์ Android หลายพันล้านเครื่องทั่วโลก แล็ปท็อป GPU ไปจนถึงเครื่องทำงานของนักพัฒนาและตัวเร่งประมวลผล
สำหรับโมเดลฝั่งอุปกรณ์ปลายทางอย่าง E2B และ E4B นั้น Google เน้นที่ความสามารถหลายรูปแบบ การประมวลผลความหน่วงต่ำ และการทำงานร่วมกับระบบนิเวศได้อย่างราบรื่น มากกว่าการไล่เพิ่มจำนวนพารามิเตอร์
ความสามารถหลักของ Gemma 4
- การใช้เหตุผลขั้นสูง รองรับการวางแผนหลายขั้นตอนและตรรกะเชิงลึก โดย Google ระบุว่ามีการปรับปรุงอย่างมีนัยสำคัญในเรื่องคณิตศาสตร์และมาตรฐานวัดการทำตามคำสั่ง
- ระบบการทำงานแบบเอเจนต์ รองรับการเรียกใช้ฟังก์ชัน, ผลลัพธ์ JSON แบบมีโครงสร้าง และคำสั่งระบบแบบในตัว ทำให้นักพัฒนาสามารถสร้างตัวแทนอัตโนมัติที่เชื่อมต่อกับเครื่องมือและ API ต่าง ๆ ได้
- การสร้างโค้ด รองรับการเขียนโค้ดแบบออฟไลน์ได้คุณภาพสูง เปลี่ยนเครื่องทำงานให้กลายเป็นผู้ช่วยเขียนโค้ด AI ที่ประมวลผลในเครื่องเป็นหลัก
- การมองเห็นและเสียง ทุกโมเดลประมวลผลวิดีโอและภาพแบบในตัว รองรับความละเอียดแบบยืดหยุ่น และทำงานได้ดีกับการอ่านตัวอักษรจากภาพ (OCR) และการอ่านแผนภูมิ ขณะที่โมเดล E2B และ E4B ยังรองรับอินพุตเสียงสำหรับการรู้จำเสียงพูดด้วย
- หน้าต่างบริบทที่ยาวขึ้น โมเดลอุปกรณ์ปลายทางรองรับหน้าต่างบริบท 128K ส่วนโมเดลขนาดใหญ่รองรับสูงสุด 256K ทำให้สามารถส่งคลังโค้ดหรือเอกสารยาว ๆ เข้าไปในพรอมต์เดียวได้
- รองรับกว่า 140 ภาษา ช่วยให้นักพัฒนาสร้างแอปพลิเคชันที่ครอบคลุมผู้ใช้ทั่วโลก
โมเดลหลากขนาด ตอบโจทย์ทุกการใช้งาน
Google ปล่อย Gemma 4 ออกมาหลายขนาด โดยแต่ละตัวออกแบบมาสำหรับฮาร์ดแวร์และกรณีการใช้งานที่แตกต่างกัน
- 26B (การผสมผู้เชี่ยวชาญ) เน้นเรื่องความหน่วงต่ำ โดยเปิดใช้งานเพียง 3.8 พันล้านพารามิเตอร์จากทั้งหมดในระหว่างการอนุมาน ทำให้ได้จำนวนโทเคนต่อวินาทีที่รวดเร็วมาก
- 31B (แบบหนาแน่น) เน้นคุณภาพดิบสูงสุด เหมาะสำหรับการปรับแต่งเป็นพื้นฐาน โดยเวอร์ชัน bfloat16 แบบไม่บีบอัดสามารถรันได้บน NVIDIA H100 GPU ตัวเดียว ส่วนเวอร์ชันบีบอัดรันได้บน GPU สำหรับผู้บริโภคทั่วไป
การเปิดตัว Gemma 4 สะท้อนกลยุทธ์ของ Google ที่ต้องการครองตลาดโมเดลแบบเปิดด้วยการทำให้ AI ระดับแนวหน้าเข้าถึงได้ง่ายที่สุด ในขณะที่ Meta เดินหน้ากับ Llama และ Mistral ยังคงเป็นผู้เล่นสำคัญในฝั่งยุโรป Google เลือกโจมตีด้วยความหลากหลายของขนาดโมเดลและความสามารถด้านหลายรูปแบบที่ครบครัน
ที่น่าจับตาคือการที่ Google ให้ความสำคัญกับ AI บนอุปกรณ์มากขึ้นเรื่อย ๆ ซึ่งสอดคล้องกับเทรนด์ที่อุตสาหกรรมกำลังเปลี่ยนจากการพึ่งพาคลาวด์อย่างเดียว มาสู่การประมวลผล AI บนอุปกรณ์ของผู้ใช้โดยตรง ทั้งเพื่อความเร็ว ความเป็นส่วนตัว และการลดต้นทุน
ตัวอย่างความสำเร็จที่ Google ยกมาก็น่าสนใจ ไม่ว่าจะเป็น INSAIT ที่สร้างโมเดลภาษาบัลแกเรีย (BgGPT) หรือการร่วมมือกับ Yale University ในการค้นหาแนวทางใหม่สำหรับการรักษามะเร็งผ่านโปรเจกต์ Cell2Sentence-Scale ซึ่งแสดงให้เห็นว่าโมเดลแบบเปิดที่ปรับแต่งได้ง่ายนั้นมีศักยภาพมหาศาลในการนำไปต่อยอด
ที่มา: Blog Google
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด

กระทรวงการอุดมศึกษา วิทยาศาสตร์ วิจัยและนวัตกรรม หรือ อว. ออกประกาศแนวทางการเคลื่อนย้ายหรือการแลกเปลี่ยนบุคลากร พ.ศ. 2569 เปิดทางให้อาจารย์ นักวิจัย และบุคลากรในสังกัดไปปฏิบัติงานช...
 0
0

บีโอไอยืนยันมาตรการส่งเสริมเปิดกว้างสำหรับผู้ประกอบการไทยและต่างชาติ โดยพิจารณาจากคุณภาพของโครงการ ที่ผ่านมาส่งเสริมผู้ผลิตชิ้นส่วนไทยเป็นจำนวนมาก อีกทั้งบริษัทไทยที่ดำเนินธุรกิจอย...
0

Huawei เปิดตัว Thailand AI Ecosystem Initiative พร้อมนำ Agentic Infrastructure และ CodeArts Agent เข้าไทย เชื่อมภาครัฐ ธุรกิจ มหาวิทยาลัย และนักพัฒนา เพื่อเร่งการใช้ AI ในองค์กรและ...
0
