
The risks of developing AI, and how businesses can mitigate them
When it comes to technology, there are many trends that fail to live up to the hype, coming and going in a matter of months.
Artificial intelligence (AI) - and the host of buzzwords associated with it - is not one of them, according to Liu Feng Yuan, co-founder and CEO at Singapore-based company BasisAI. Instead, he believes that, thanks to AI, “very little data in Singapore is truly big data because technology has evolved to a point where we can truly process all of it.”
 Speaking at the inaugural LIT DISCOvery conference, co-organised by Young NTUC and Lifelong Learning Institute and powered by National Youth Council, Liu explains that this has helped humans in workplaces all over the world to become “better and better at using data to make decisions [instead of doing it] because your boss says so, or because it is a gut feeling.”
Speaking at the inaugural LIT DISCOvery conference, co-organised by Young NTUC and Lifelong Learning Institute and powered by National Youth Council, Liu explains that this has helped humans in workplaces all over the world to become “better and better at using data to make decisions [instead of doing it] because your boss says so, or because it is a gut feeling.”
As it turns out, businesses are starting to believe in the power of AI, too. According to a report by the International Data Corporation, global spending on AI systems is expected to hit US$35.8 billion by the end of 2019, which is an increase of 44 percent over the amount spent in 2018.
That said, many people are still on the fence when it comes to AI. This hesitation stems from the fact that computers can perform certain tasks far better than humans, such as recognising faces in photos. However, Liu emphasizes that computers are only able to excel in “very narrow tasks,” and not in things that require “common sense and creativity.
Because of this, businesses continue to face certain risks when it comes to developing AI solutions for the workplace. Here are some of the governance challenges that businesses face when it comes to AI, and how they might be able to overcome them.
Need for context and common sense
As mentioned previously, AI has reached a level where it is able to process and identify certain characteristics in photos very accurately. However, on its own, it cannot distil that down to the most relevant information based on the context of the image.
Liu shares the example of a government agency collecting municipal feedback and complaints from citizens. During his stint at GovTech Singapore, he and his team had to figure out a way to pick out the right information from images that citizens were sending in, so that public service officers could more easily address them.
Without context, though, running an image of an overflowing rubbish bin through their AI system might simply yield the following keywords: ‘Blue plastic recycling rolling trash bin’. While it does identify the object correctly, it completely misses what’s truly important - that the rubbish bin is overflowing. Out of the box, the algorithm in question doesn’t know what the agency is concerned about, and hence, is unable to provide useful information.
Unfortunately, this means that it is rather simple to deceive the AI system. By adding a noise filter, you can trick an app into identifying a panda as a gibbon instead:
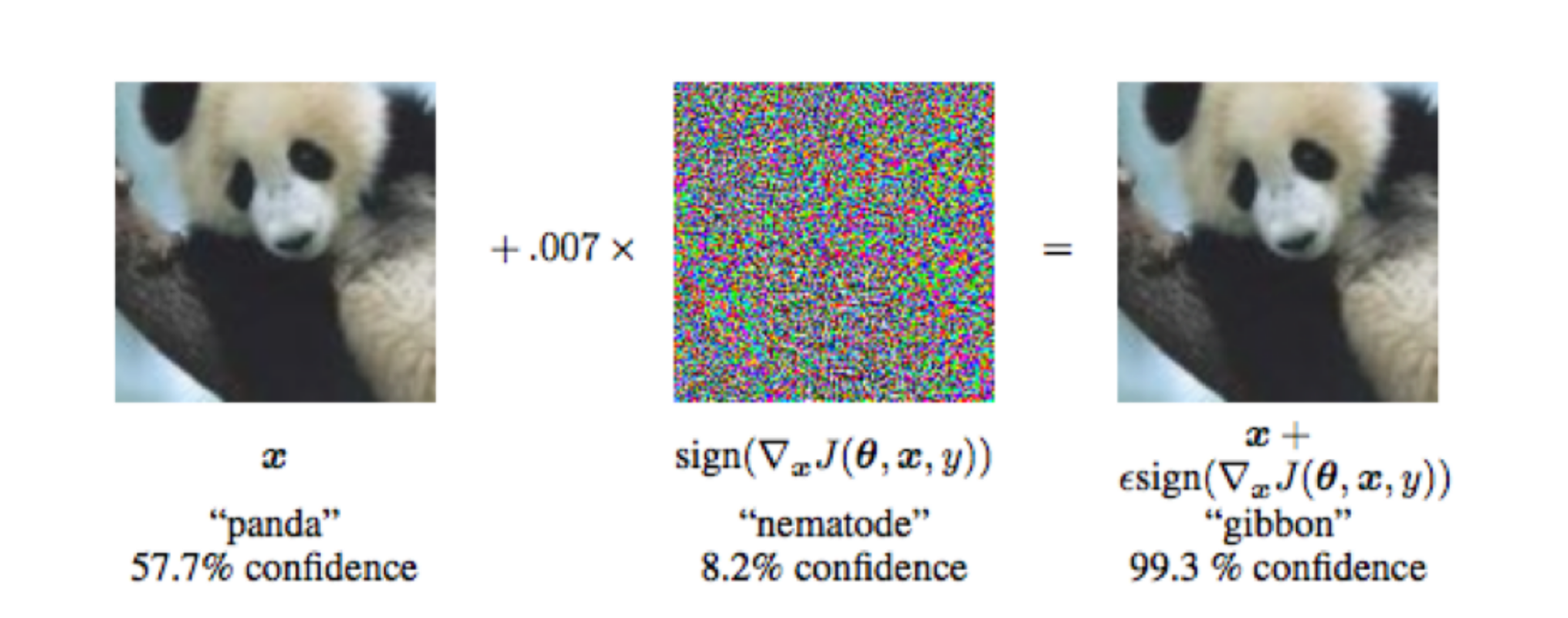 Such inputs are known as adversarial examples, which are purposefully designed and introduced to cause an AI model to make mistakes. Within the context of a business - or worse still, a government organization like MSO - this opens up an opportunity for hackers, or employees with malicious intents, to mislead end users.
Such inputs are known as adversarial examples, which are purposefully designed and introduced to cause an AI model to make mistakes. Within the context of a business - or worse still, a government organization like MSO - this opens up an opportunity for hackers, or employees with malicious intents, to mislead end users.
Learning from biased past data
If a child picks up the wrong habit or teaching from young, he or she might end up making the wrong decisions and choices further down the road. In the same way, AI systems can also go astray if they learn from past data that is biased in nature.
Liu points to an incident that happened in 2015, when a black software developer discovered that Google was classifying African-Americans as gorillas in the company’s Photos service. Google was also picking up certain stereotypes that people commonly hold, and making incorrect associations based on these biases, such as equating terms like ‘diva’ with ‘women’. Basically, “inheriting all the stereotypes that we expect from society,” explains Liu.
Naturally, this caused the search engine giant a huge amount of embarrassment and negative branding - something that they’re still unable to recover from to this day.
Open up the black box
A big reason why businesses are often unable to prevent such incidents from occurring is that AI is similar to a black box - most don’t really understand what’s happening within. As data scientists and engineers work towards making AI even smarter, there is a need for the management team and leaders to provide better governance over how AI is being used within their organizations, Liu says.
The need for AI governance is all the more pertinent for bigger companies with legacy systems, who don’t have the opportunity to think of AI “from the very beginning [...] they tend to only do very small-scale experiments with AI, and hence struggle to get business value from it,” he continues. “Technology companies who are digitally native - with engineers and data scientists as part of their leadership - have an advantage here.”
Unfortunately, many are happy to leave the black box unopened and “let the computer do what it’s supposed to do,” which often results in the issues stated earlier. And in larger organizations, there can be more than a hundred algorithms running at the same time, reveals Liu.
The matter gets complicated further when only one or two people are left in charge of them - if they ever leave the organization, no one would know when was the AI model last trained, what it was trained on, and so on. Many tech companies face a situation where data scientists would pass on an algorithm to the engineers for deployment, which would then take more than four months to happen because of limited knowledge.
In order to ensure that the AI system is constantly running the way that it’s supposed to, a systemic way of auditing and governing all the algorithms needs to be put in place. Liu suggests that businesses open up the black box with the following measures:
- Internal expertise: have data scientists on staff
- Version control: ensure that changes and revisions are identified clearly and saved
- Data lineage: making sure that whenever an AI model is trained, the type of data it was trained on is logged down
- Ongoing monitoring of algorithms: after deployment, continually ensure that predictions made by algorithms are accurate
This article is written by Daniel, Co-founder & Managing director of With Content, a content marketing agency.
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด

Techsauce Global Summit 2026: Diving Deep into Southeast Asia's Largest Tech Conference
Techsauce Global Summit 2026 is the largest tech and business conference in Southeast Asia. Organized continuously for over a decade, it serves as a vital ecosystem connector bridg...
 0
0

Once criticized for a "terrible" system, CP AXTRA is now a regional retail tech leader. Discover Tanit Chearavanont’s journey of building a 400-person tech team, a proprietary OMS,...
0

Techsauce CEO shares the N.E.X.T framework for building an AI-era business: Navigate Technology, Experiment Fast, Exponential Thinking, and Trust & Tribe — straight from Davos insi...
0
