
Adobe พัฒนา ‘Corrective AI’ ฟีเจอร์เปลี่ยนเสียงพากย์ให้สดใส พร้อมลบเสียงรบกวน และลบเพลงลิขสิทธิ์ออก
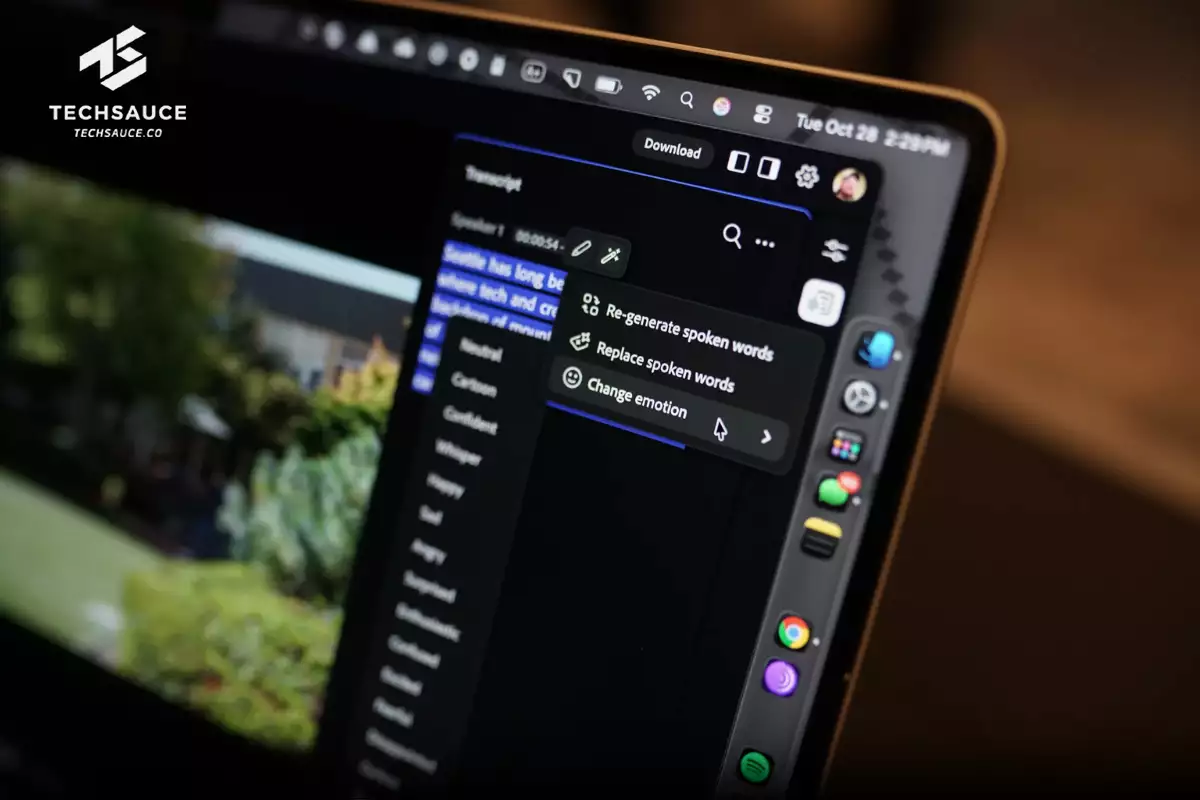
วงการ Post-Production มีเรื่องให้ตื่นเต้นอีกครั้ง เมื่อ Adobe เผยตัวอย่างเทคโนโลยี AI ใหม่ล่าสุดในงาน ‘MAX Sneaks’ ซึ่งเป็นเวทีโชว์เคสโปรเจกต์ต้นแบบสุดล้ำของบริษัท โดยพระเอกของงานนี้คือ ‘Corrective AI’ เครื่องมือที่อาจเปลี่ยนวิธีคิดของเราเกี่ยวกับการแก้ไขเสียงพากย์ไปตลอดกาล
ลองนึกภาพว่าคุณมีไฟล์เสียงพากย์ที่สมบูรณ์แบบ แต่ติดอยู่อย่างเดียวคือน้ำเสียงที่ราบเรียบและน่าเบื่อจนเกินไป แทนที่จะต้องเสียเวลาจองห้องอัดและเรียกนักพากย์มาอัดใหม่ทั้งหมด Adobe สาธิตให้เห็นว่า Corrective AI ทำได้อย่างไร
เพียงแค่เปิด Transcript (ข้อความถอดเสียง) ขึ้นมา ไฮไลต์ประโยคที่มีปัญหา แล้วเลือกอารมณ์ที่ต้องการจากลิสต์ที่ตั้งค่าไว้ ในพริบตา เสียงที่เคยเรียบเฉยก็เปลี่ยนเป็นเสียงที่มั่นใจหรือแม้กระทั่งเปลี่ยนเป็นเสียงกระซิบ ได้อย่างน่าทึ่ง นี่คือก้าวสำคัญที่ต่อยอดมาจากฟีเจอร์ 'Generative Speech' ใน Firefly แต่เน้นไปที่การแก้ไข (Corrective) สิ่งที่มีอยู่เดิมแทนที่จะสร้างใหม่ทั้งหมด ซึ่งตอบโจทย์การทำงานจริงในสายงานโปรดักชันได้ตรงจุดกว่า
‘Project Clean Take’ AI ผู้ช่วยตัดต่อเสียงขั้นเทพ
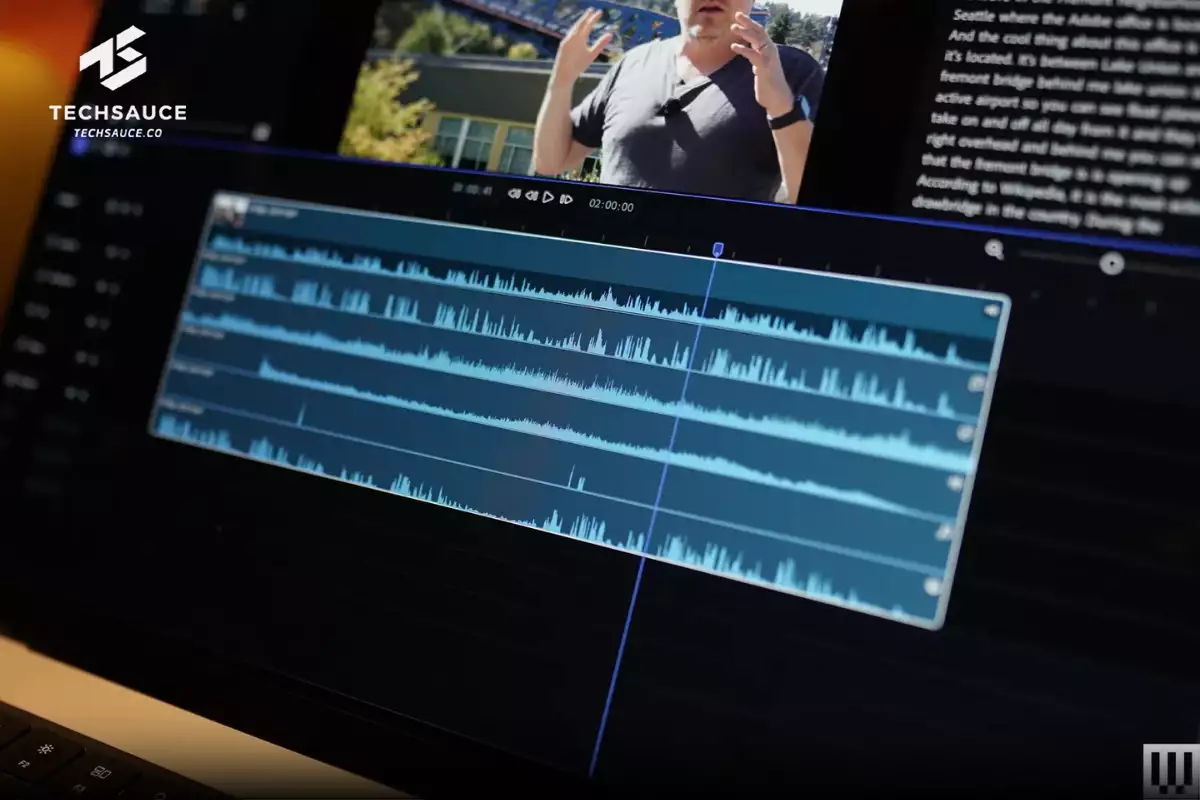
ยังไม่หมดแค่นั้น Adobe ยังเปิดตัวอีกหนึ่งต้นแบบที่น่าทึ่งไม่แพ้กันในชื่อ ‘Project Clean Take’ นี่คือ AI ที่ออกแบบมาเพื่อลบแทร็กเสียงเดียวที่ยุ่งเหยิง ให้กลายเป็นแทร็กย่อยๆ ที่สะอาดสะอ้านมากขึ้น
ในเดโมที่ทาง WIRED ซึ่งเป็นผู้เขียนบทความได้รับชม Lee Brimelow จาก Adobe แสดงให้เห็นว่า AI สามารถแยกเสียงพูด, เสียงรบกวนรอบข้าง (Ambient Noise), และซาวด์เอฟเฟกต์ (SFX) ออกจากกันได้แม่นยำขนาดไหน (ปัจจุบันต้นแบบจำกัดที่ 5 แทร็ก)
ลองนึกถึงสถานการณ์ที่ผู้บรรยายกำลังพูดอยู่หน้าสะพานชัก และจู่ๆ ก็มีเสียงระฆังดังลั่นกลบเสียงพูดจนหมด Project Clean Take สามารถเข้าไปแยกเสียงระฆังนั้นออกไป เหลือเพียงเสียงพูดที่ชัดเจน หรือแม้กระทั่งปรับลดเสียงระฆังนั้นให้เบาลงในระดับที่ต้องการได้
หมดปัญหากลัว 'Copyright Strike'
อีกหนึ่งกรณีศึกษาที่ครีเอเตอร์ต้องเจอเป็นประจำคือการถ่ายทำในที่สาธารณะแล้วดันมีเพลงลิขสิทธิ์ดังเข้ามาในวิดีโอ ซึ่งเป็นทางด่วนสู่การโดนแจ้งเตือนละเมิดลิขสิทธิ์ (Copyright Strike) บน YouTube
Project Clean Take แก้ปัญหานี้โดยการแยกเพลงนั้นออกมา แล้วแทนที่ด้วยเพลงที่คล้ายกันจากคลัง Adobe Stock พร้อมทั้งปรับแต่งเสียงก้อง (Reverb) และบรรยากาศ (Ambiance) ให้เหมือนกับว่ามันถูกเล่นอยู่ในสถานที่นั้นจริงๆ ทั้งหมดนี้เกิดขึ้นด้วยการคลิกเพียงไม่กี่ครั้ง
AI สร้าง Sound Effect เอง แถมสั่งงานได้เหมือน ChatGPT
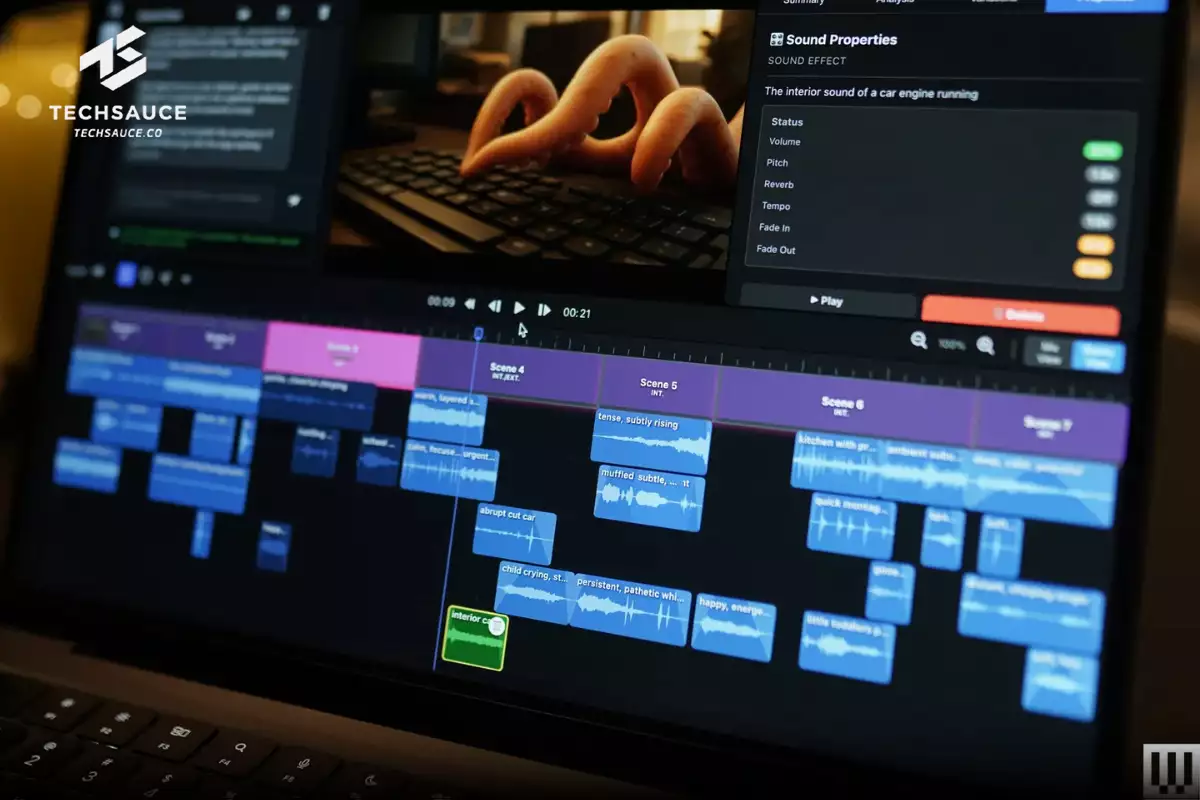
ในโชว์เคสเดียวกัน Adobe ยังพรีวิว AI ที่สามารถสร้าง Sound Effect (SFX) ได้เองอัตโนมัติ โดย AI จะวิเคราะห์วิดีโอ แบ่งเป็นฉากๆ (เช่น ฉากนาฬิกาปลุก, ฉากขับรถ) แล้วสร้าง SFX ที่เหมาะสมเติมเข้าไปให้ทันที
แม้ว่าผลลัพธ์บางส่วนจะยังไม่สมบูรณ์แบบ (เช่น เสียงนาฬิกาปลุกยังไม่สมจริง) แต่จุดที่น่าสนใจคือ Adobe ได้ผสานอินเทอร์เฟซแบบสนทนา (Conversational Interface) เข้าไปด้วย
แทนที่จะต้องไปนั่งค้นหาไฟล์เสียงเอง ผู้ใช้สามารถพิมพ์บอก AI เหมือนคุยกับ ChatGPT ได้เลยว่า 'ช่วยเพิ่มเสียงแอมเบียนต์ของรถในฉากนี้หน่อย' จากนั้น AI ก็จะไปค้นหาฉาก สร้างเสียง และวางมันลงในไทม์ไลน์ให้ทันที
อนาคตผลกระทบต่อวงการสร้างสรรค์
แน่นอนว่าฟีเจอร์ทั้งหมดนี้ยังเป็นเพียง 'Sneaks' หรือต้นแบบที่ยังไม่เปิดให้ใช้งานจริง แต่อย่าลืมว่าฟีเจอร์ 'Harmonize' ใน Photoshop ที่เคยโชว์ในงานปีก่อน ตอนนี้ก็กลายเป็นฟีเจอร์มาตรฐานไปแล้ว Adobe คาดว่าเราอาจได้เห็นเทคโนโลยีเหล่านี้ในผลิตภัณฑ์จริงช่วงปี 2026
การเปิดตัวครั้งนี้เกิดขึ้นในจังหวะที่ละเอียดอ่อน เพียงไม่กี่เดือนหลังจากที่นักพากย์วิดีโอเกมในสหรัฐฯ เพิ่งยุติการประท้วงหยุดงานอันยาวนาน เพื่อเรียกร้องการคุ้มครองสิทธิ์จากการใช้ AI สร้างเสียงของพวกเขาซ้ำ
แม้ว่า Corrective AI จะไม่ได้สร้างเสียงใหม่จากศูนย์ แต่การที่มันสามารถดัดแปลงอารมณ์การแสดงของนักพากย์ที่มีอยู่เดิมได้ ก็ถือเป็นอีกหนึ่งหมุดหมายสำคัญที่ตอกย้ำว่า AI กำลังเข้ามาเปลี่ยนอุตสาหกรรมสร้างสรรค์อย่างรวดเร็วและหลีกเลี่ยงไม่ได้
ที่มา: Wired
_____________________
เตรียมความพร้อมให้ธุรกิจของคุณก้าวสู่ยุค AI อย่างมั่นใจ ด้วยการพัฒนา people, process และ technology อย่างครบวงจรไปกับ Techsauce
ร่วมสำรวจแนวทางและโอกาสในการเปลี่ยนผ่านสู่ AI-first organization ไปกับเรา techsauce
เพื่อนร่วมทางในการพัฒนา AI journey ของคุณ ได้ที่: https://services.techsauce.co/contact-us
หรืออีเมล [email protected]
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด


เมื่อคอมพิวเตอร์ทั่วไปถอดรหัสใช้ 4.7 พันล้านปี แต่ควอนตัมทำเสร็จใน 8 ชม. เจาะลึกบทบาท depa x IBM ดัน Thailand Quantum Readiness ปูทางสร้าง Ecosystem ในก่อนสายเกินแก้...
 0
0

กระทรวงการอุดมศึกษา วิทยาศาสตร์ วิจัยและนวัตกรรม หรือ อว. ออกประกาศแนวทางการเคลื่อนย้ายหรือการแลกเปลี่ยนบุคลากร พ.ศ. 2569 เปิดทางให้อาจารย์ นักวิจัย และบุคลากรในสังกัดไปปฏิบัติงานช...
0

บีโอไอยืนยันมาตรการส่งเสริมเปิดกว้างสำหรับผู้ประกอบการไทยและต่างชาติ โดยพิจารณาจากคุณภาพของโครงการ ที่ผ่านมาส่งเสริมผู้ผลิตชิ้นส่วนไทยเป็นจำนวนมาก อีกทั้งบริษัทไทยที่ดำเนินธุรกิจอย...
0
