
รู้จัก Memento-skills เครื่องมือแก้จุดอ่อน AI Agent ให้ AI สร้าง และพัฒนา Skill ได้เอง แก้ปัญหาหยุดเรียนรู้หลัง Deploy
นักวิจัยจากหลายมหาวิทยาลัยร่วมกันพัฒนา “Memento-Skills” เฟรมเวิร์กใหม่ที่มีเป้าหมายชัดเจน คือการแก้ข้อจำกัดสำคัญของ AI agent ในปัจจุบัน นั่นคือ การไม่สามารถเรียนรู้หรือปรับตัวได้หลังจากถูก Deploy ไปใช้งานจริง
แนวคิดของระบบนี้ไม่ใช่การปรับปรุงโมเดล LLM โดยตรง แต่เป็นการเพิ่ม “ชั้นของความสามารถ” เข้าไปภายนอก เพื่อเปิดทางให้ Agent สามารถสร้าง ปรับปรุง และสะสม Skill ของตัวเองได้อย่างต่อเนื่อง โดยไม่ต้องเทรนโมเดลใหม่ทุกครั้ง
Jun Wang หนึ่งในผู้เขียนงานวิจัยอธิบายว่า Memento-Skills ทำหน้าที่เสริม Continual learning ให้กับ Agent ยุคใหม่ และสามารถนำไปใช้งานร่วมกับระบบเดิมได้ทันที เช่น OpenClaw และ Claude Code โดยไม่ต้องแก้ไขโครงสร้างหลักของโมเดล

ปัญหา AI agent ที่ “หยุดเรียนรู้” หลัง Deploy
โดยธรรมชาติของโมเดลภาษา เมื่อผ่านการ Train และถูก Deploy แล้ว พารามิเตอร์จะถูกตรึงไว้ ส่งผลให้ Agent ไม่สามารถเรียนรู้สิ่งใหม่จากการใช้งานจริงได้ช
ในทางปฏิบัติ ทีมพัฒนามักใช้วิธี “เสริมจากภายนอก” เช่น การเขียน Skill เพิ่มด้วยมือ หรือการปรับ Prompt เพื่อให้ตอบได้ดีขึ้น อย่างไรก็ตาม วิธีเหล่านี้ยังเป็นเพียงการปรับแต่งพฤติกรรม ไม่ใช่การเรียนรู้ที่แท้จริง และมักไม่สามารถนำไปใช้ข้าม Task ได้อย่างมีประสิทธิภาพ
ขณะเดียวกัน แนวทางอย่าง Rag ที่อาศัย Semantic similarity ในการค้นหาความรู้ ก็มีข้อจำกัดในตัวเอง เพราะความคล้ายของภาษาไม่ได้รับประกันว่าคำตอบจะเหมาะกับบริบทของงาน ตัวอย่างเช่น Agent อาจเลือกขั้นตอน “รีเซ็ตรหัสผ่าน” มาใช้กับ “คืนเงิน” เพียงเพราะใช้คำศัพท์ใกล้เคียงกัน แม้เนื้อหาจะไม่เกี่ยวข้องโดยตรง
จาก Memory ธรรมดา สู่ Skill ที่พัฒนาได้เอง
 ที่มา: GitHub - Memento-Skills
ที่มา: GitHub - Memento-Skills
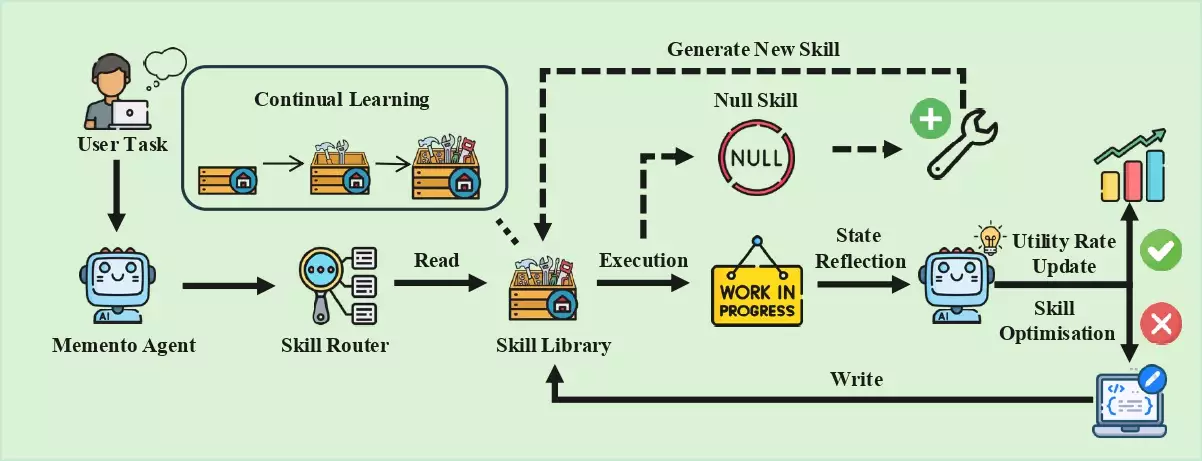
Memento-Skills เสนอแนวคิดใหม่ โดยเปลี่ยน Memory ให้กลายเป็น 'คลัง Skill ที่พัฒนาได้'
แทนที่จะเก็บเพียงประวัติการทำงาน ระบบจะสร้าง Skill ในรูปแบบที่มีโครงสร้างชัดเจน และสามารถนำไปใช้ซ้ำหรือปรับปรุงต่อได้ โดยแต่ละ Skill ประกอบด้วย 3 ส่วนสำคัญ ได้แก่
- Declarative specification ที่อธิบายว่า Skill คืออะไร และควรใช้ในสถานการณ์แบบใด
- Instruction และ Prompt ที่กำหนดแนวทางการคิดของ Agent
- Executable code ที่สามารถนำไปใช้ทำงานจริงได้
โครงสร้างนี้ทำให้ Skill ไม่ใช่แค่บันทึกสิ่งที่เคยทำแต่กลายเป็น “หน่วยความสามารถ” ที่สามารถนำกลับมาใช้และพัฒนาต่อได้อย่างเป็นระบบ
เรียนรู้จากการใช้งานจริงแบบ Reflective
หัวใจของระบบคือ Read-write reflective learning ที่ทำให้ Agent เรียนรู้จากผลลัพธ์ของตัวเอง ซึ่งเปลี่ยน Memory จาก Passive storage ให้กลายเป็น Active learning system
เมื่อ Agent ได้รับ Task ใหม่ ระบบจะใช้ Skill router เพื่อเลือก Skill ที่เหมาะสมที่สุด โดยพิจารณาจากลักษณะการใช้งานจริงหรือพฤติกรรม ไม่ใช่เพียงความคล้ายของข้อความ
หาก Skill ที่เลือกมาไม่สามารถแก้ปัญหาได้ Agent จะวิเคราะห์สาเหตุของความล้มเหลว และดำเนินการปรับปรุงโดยอัตโนมัติ ไม่ว่าจะเป็นการแก้ไข Prompt ปรับโค้ด หรือสร้าง Skill ใหม่ขึ้นมา
กระบวนการเรียนรู้เหล่านี้ถูกสนับสนุนด้วย Offline reinforcement learning ซึ่งเรียนรู้จากผลลัพธ์ของการทำงานจริง ทำให้การพัฒนา Skill มีทิศทางที่สอดคล้องกับประสิทธิภาพจริง ไม่ใช่เพียงการประเมินจากข้อความ
ในขณะเดียวกัน ระบบยังมี Unit-test gate เพื่อทดสอบ Skill ที่ถูกแก้ไขก่อนนำไปใช้งานจริง ช่วยลดความเสี่ยงของ Regression หรือการที่ระบบแย่ลงหลังการปรับปรุง
ประสิทธิภาพเพิ่มขึ้นอย่างมีนัยสำคัญ
ทีมวิจัยประเมินระบบบน Benchmark ที่มีความซับซ้อนสูง ได้แก่ Gaia ซึ่งต้องใช้ Multi-step reasoning และการทำงานร่วมกับเครื่องมือ และ Humanity’s last exam (Hle) ซึ่งครอบคลุมโจทย์ระดับผู้เชี่ยวชาญในหลายสาขา
ผลการทดสอบแสดงให้เห็นถึงการปรับปรุงที่มีนัยสำคัญ โดย Gaia จาก 52.3% เพิ่มเป็น 66.0% และ Hle จาก 17.9% เพิ่มเป็น 38.7%
ในด้านการเลือกใช้ Skill ระบบ Skill router สามารถเพิ่มอัตราความสำเร็จของงานเป็น 80% เมื่อเทียบกับ 50% ของวิธี Retrieval แบบดั้งเดิมอย่าง Bm25
อีกหนึ่งจุดที่น่าสนใจคือ ระบบสามารถเริ่มต้นจาก Seed skill เพียงไม่กี่รายการ เช่น การค้นเว็บหรือการใช้ Terminal ก่อนจะค่อย ๆ ขยาย Skill library ของตัวเองขึ้นเป็นหลายสิบหรือหลายร้อยรายการตามประสบการณ์การใช้งานจริง
เหมาะกับงานที่มีรูปแบบชัดเจน
แม้แนวทางนี้จะช่วยให้ Agent พัฒนาได้ต่อเนื่อง แต่ประสิทธิภาพยังขึ้นอยู่กับลักษณะของ Task หากงานมีโครงสร้างหรือรูปแบบซ้ำกัน ระบบจะสามารถถ่ายโอนความรู้และพัฒนา Skill ได้อย่างมีประสิทธิภาพ
ในทางกลับกัน หาก Task มีความหลากหลายสูง หรือไม่เกี่ยวข้องกัน การเรียนรู้ข้าม Task จะทำได้ยากขึ้น นอกจากนี้ งานที่เกี่ยวข้องกับ Physical agent หรือการตัดสินใจระยะยาวยังคงเป็นพื้นที่ที่ต้องการการวิจัยเพิ่มเติม
แม้ระบบจะมี Unit-test gate เป็นกลไกพื้นฐานในการควบคุมคุณภาพ แต่การนำไปใช้งานในระดับองค์กรยังต้องมีการออกแบบระบบกำกับดูแลเพิ่มเติม
นักวิจัยแนะนำว่าการให้ Agent ปรับปรุงตัวเองควรอยู่ภายใต้แนวคิดของ Guided self-development หรือการพัฒนาแบบมีกรอบ มากกว่าการเปิดให้เรียนรู้แบบไร้ขอบเขต ซึ่งอาจนำไปสู่ความเสี่ยงในระยะยาว
ปัจจุบัน Memento-Skills เปิดให้ใช้งานแล้วในรูปแบบ Open source บน GitHub และถือเป็นอีกหนึ่งแนวทางที่สะท้อนทิศทางสำคัญของ AI agent ในอนาคต นั่นคือการขยับจากระบบที่ทำตามคำสั่งไปสู่ระบบที่สามารถ “พัฒนาและเรียนรู้จากประสบการณ์ของตัวเอง” ได้อย่างต่อเนื่อง
อ้างอิง: VentureBeat
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด

สรุปวิสัยทัศน์ วิทัย รัตนากร ผู้ว่าการธนาคารแห่งประเทศไทย จากงาน Capital with Porpose 2026 : Unlocking ESG Value through Green Finance ที่ชี้ให้เห็นว่า ความยั่งยืน ไม่ใช่ทางเลือกแต...
 0
0

Huawei เปิดวิสัยทัศน์ Token Monetization ในงาน MWC Shanghai 2026 ชี้ AI กำลังเปลี่ยนโมเดลธุรกิจโทรคมนาคม จากการขาย Data สู่การสร้างรายได้จากบริการ AI และ 5G-A...
0

Anthropic เดือด แฉ Alibaba สร้างบัญชีผี 25,000 บัญชี ดูดข้อมูล Claude ไปเทรน AI ของตัวเอง
Anthropic แฉ Alibaba สร้างบัญชีผี 25,000 บัญชี ลอบดูดข้อมูล (Distillation) จาก Claude ไปเทรน AI ของตัวเอง ชี้เป็นแคมเปญขโมยข้อมูล AI ครั้งใหญ่สุดที่เคยมีมา...
0
