
รู้จัก ‘Nemotron 3 Super’ Open Source ล่าสุดจาก NVIDIA โมเดล AI สำหรับระบบ Agentic Reasoning ประมวลผลเร็วกว่ารุ่นเดิม 5 เท่า

NVIDIA เปิดตัว Nemotron 3 Super โมเดลภาษาขนาดใหญ่รุ่นใหม่ที่ออกแบบมาเพื่อระบบ Agentic AI หรือ AI ที่ทำงานอัตโนมัติโดยเฉพาะ ตัวโมเดลมีพารามิเตอร์ทั้งหมด 120 พันล้านตัว แต่เปิดใช้จริงเพียง 12 พันล้านตัวต่อการประมวลผลหนึ่งครั้ง จุดเด่นคือเป็น Open Source เต็มรูปแบบ ทั้งน้ำหนักโมเดล ชุดข้อมูล และสูตรการเทรน ให้นักพัฒนานำไปปรับใช้ได้เองทันที
AI อัตโนมัติต้องการอะไรที่แตกต่าง
ระบบ AI ที่ทำงานหลายขั้นตอนต่อเนื่องกัน เช่น agent ที่เขียนโค้ด ค้นหาข้อมูล และตัดสินใจเองได้ มีความต้องการที่ต่างจาก chatbot ทั่วไปมาก เพราะในแต่ละรอบการทำงาน ระบบจะต้องส่งข้อมูลย้อนกลับมหาศาล ทั้งประวัติการสนทนา ผลลัพธ์ของ tool และขั้นตอนการคิด ซึ่งมากกว่าการสนทนาปกติถึง 15 เท่า
ปัญหาที่ตามมาคือในงานยาว ๆ ตัว agent จะค่อย ๆ "ลืม" เป้าหมายเดิมและเริ่มเบี่ยงออกทิศทาง นอกจากนี้ การใช้โมเดลขนาดใหญ่กับทุกงานย่อยยังสร้างต้นทุนที่สูงและทำให้ระบบช้าเกินจะนำไปใช้จริง Nemotron 3 Super ถูกออกแบบมาเพื่อแก้ปัญหาทั้งสองนี้โดยตรง
สี่นวัตกรรมที่ทำให้ Super แตกต่าง
Hybrid Mamba-Transformer คือสถาปัตยกรรมหลักของโมเดล โดยผสมสองแนวทางเข้าหากัน Mamba-2 รับหน้าที่ประมวลผลข้อความยาวอย่างมีประสิทธิภาพด้วยการใช้หน่วยความจำน้อย ขณะที่ Transformer ทำหน้าที่ดึงข้อมูลเฉพาะจุดได้อย่างแม่นยำ ผลคือโมเดลอ่านทั้ง codebase หรือเอกสารยาวนับพันหน้าได้โดยไม่สะดุด รองรับบริบทสูงสุด 1 ล้าน token ซึ่งเพียงพอสำหรับงานโปรเจกต์ขนาดใหญ่
Latent MoE (Mixture-of-Experts) คือระบบที่ให้โมเดลเรียกใช้ "ผู้เชี่ยวชาญ" เฉพาะทางในแต่ละงาน แทนที่จะประมวลผลทุกอย่างพร้อมกัน สิ่งที่ Super ทำต่างออกไปคือการบีบอัดข้อมูลก่อนส่งให้ผู้เชี่ยวชาญแต่ละคน ทำให้เรียกใช้ผู้เชี่ยวชาญได้มากขึ้น 4 เท่าในต้นทุนเดิม เช่น อาจมี expert เฉพาะสำหรับ Python และอีกตัวสำหรับ SQL โดยเปิดใช้เฉพาะเมื่อจำเป็นจริง ๆ เท่านั้น
Multi-Token Prediction (MTP) คือการเทรนให้โมเดลทำนายคำหลายคำพร้อมกันในครั้งเดียว แทนที่จะทำนายทีละคำตามแบบเดิม ทำให้การสร้างข้อความยาวเร็วขึ้นถึง 3 เท่า และยังช่วยให้โมเดลเรียนรู้การคิดแบบต่อเนื่องได้ดีขึ้นอีกด้วย
Native NVFP4 Pretraining คือการเทรนโมเดลด้วย 4-bit floating-point format ตั้งแต่ต้น ต่างจากโมเดลทั่วไปที่มักบีบอัดหลังเทรนเสร็จแล้วค่อยสูญเสียความแม่นยำ วิธีนี้ทำให้ Inference บน NVIDIA Blackwell เร็วขึ้น 4 เท่าเมื่อเทียบกับ GPU รุ่น H100 โดยยังคงความแม่นยำเดิมไว้ได้
เทรนอย่างไรให้ได้ AI ที่ทำงานได้จริง
NVIDIA แบ่งกระบวนการเทรนออกเป็นสามระยะ เริ่มจาก Pretraining บนข้อมูลกว่า 25 ล้านล้าน token เพื่อสร้างความเข้าใจภาษาและความรู้รอบด้าน จากนั้นผ่าน Supervised Fine-tuning กับตัวอย่างอีก 7 ล้านชุดที่ครอบคลุมทั้งการเขียนโค้ด การตอบคำสั่ง และความปลอดภัย เพื่อกำหนดรูปแบบการตอบสนองที่ถูกต้อง
ระยะสุดท้ายคือ Reinforcement Learning หรือการเรียนรู้เสริมกำลัง ซึ่งเป็นหัวใจที่ทำให้ Super กลายเป็น AI ที่ทำงานอัตโนมัติได้จริง โมเดลถูกฝึกใน 21 สภาพแวดล้อมจำลอง กว่า 1.2 ล้านรอบ โดยวัดผลจากการทำงานจริง ไม่ใช่แค่การตอบคำถาม เช่น สามารถเขียนโค้ดที่รันได้ เรียก tool ถูกต้อง หรือวางแผนหลายขั้นตอนได้สำเร็จหรือไม่
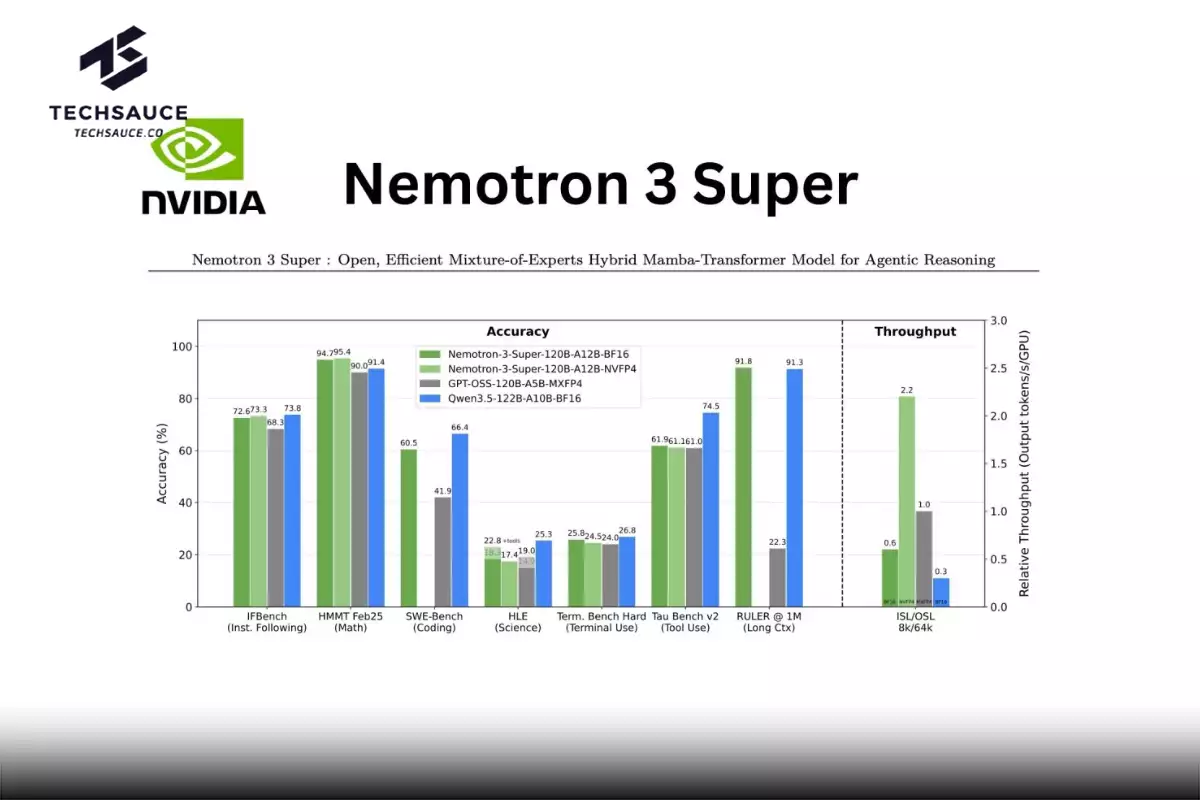
ผลลัพธ์ที่ได้
บน PinchBench ที่ใช้วัดความสามารถของโมเดลในฐานะ "สมอง" ของ AI agent Nemotron 3 Super ทำคะแนนได้ 85.6% ซึ่งสูงที่สุดในบรรดา open model ระดับเดียวกัน และบน Artificial Analysis Intelligence Index ยังทำคะแนนเหนือกว่า gpt-oss-120b ของ OpenAI อีกด้วย
NVIDIA ยังรายงานว่าโมเดลช่วยให้ NVIDIA AI-Q research agent ขึ้นอันดับ 1 บน DeepResearch Bench ซึ่งเป็น benchmark ที่วัดความสามารถค้นคว้าข้อมูลแบบหลายขั้นตอน
ใช้ Super คู่กับ Nano
NVIDIA แนะนำให้ใช้ Nemotron 3 Super และ Nano ร่วมกัน เพื่อให้ได้ประสิทธิภาพในราคาที่เหมาะสม ตัวอย่างในวงการพัฒนาซอฟต์แวร์ งาน merge request ธรรมดาให้ Nano จัดการ ส่วนงานที่ต้องเข้าใจ codebase ทั้งหมดหรือโปรเจกต์ซับซ้อนให้ Super รับไป ส่วนงานระดับสูงสุดที่ต้องการความแม่นยำเป็นพิเศษ ยังสามารถส่งต่อให้โมเดลเชิงพาณิชย์ได้
Nemotron 3 Super เปิดให้ใช้งานแล้ววันนี้ผ่าน Hugging Face, NVIDIA NIM, OpenRouter และ build.nvidia.com รวมถึง cloud providers ชั้นนำอย่าง Google Cloud, Cloudflare, DeepInfra, Fireworks AI และ Together AI นักพัฒนาที่ต้องการปรับแต่งโมเดลสามารถเริ่มต้นจาก cookbooks สำหรับ vLLM, SGLang และ TensorRT LLM บน GitHub ได้เลย
ที่มา: Nvidia
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด

ธนาคารกสิกรไทย แจ้งผลประกอบการครึ่งปีแรก ปี 2569 กำไร 27,915 ล้านบาท
นางสาวขัตติยา อินทรวิชัย ประธานเจ้าหน้าที่บริหาร ธนาคารกสิกรไทย เปิดเผยว่า เศรษฐกิจไทยในไตรมาส 2 ปี 2569 ชะลอลงจากไตรมาสแรก ท่ามกลางแรงกดดันจากปัจจัยภายนอกที่ชัดเจนขึ้น โดยเฉพาะควา...
 0
0

เอสซีบี เอกซ์ รายงานกำไรสุทธิไตรมาส 2 ปี 2569 ที่ 11,117 ล้านบาท เพิ่มขึ้นร้อยละ 9 จากไตรมาสก่อน รับรายได้ค่าธรรมเนียมและธุรกิจ Wealth ที่โต ชดเชยแรงกดดันดอกเบี้ยขาลง หนี้เสียลดเหล...
0

Data Center ดันความต้องการใช้น้ำเพิ่มสูงสุด 29 ล้านลูกบาศก์เมตรต่อปี WHAUP ชูระบบน้ำครบวงจร เสริมความพร้อม EEC รองรับคลื่นลงทุนอุตสาหกรรมแห่งอนาคต...
0
