
รู้จัก HealthBench จาก OpenAI เครื่องมือวัดความแม่นยำ AI ในการให้คำปรึกษาด้านสุขภาพ

OpenAI ได้เปิดตัวโมเดลภาษาขนาดใหญ่แบบ Open-Source ที่เรียกว่า HealthBench ซึ่งเป็นชุดข้อมูล และเกณฑ์มาตรฐานที่ออกแบบมาเพื่อวัดประสิทธิภาพของโมเดล AI ที่เกี่ยวข้องกับการให้คำปรึกษาด้านสุขภาพโดยเฉพาะ นับเป็นก้าวสำคัญของ OpenAI ในการยกระดับความน่าเชื่อถือ และความแม่นยำของ AI ในมิติที่มีความละเอียดอ่อนต่อชีวิตมนุษย์
HealthBench คืออะไร ?
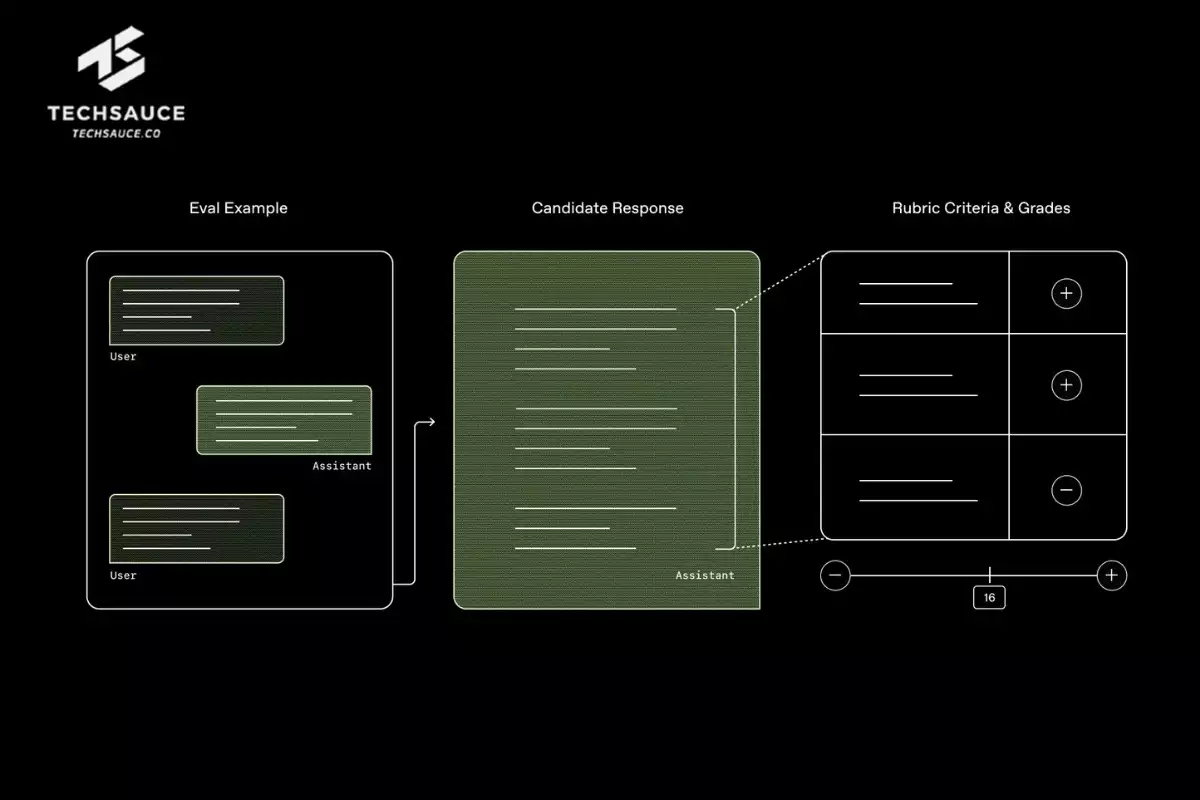
HealthBench เป็นชุดข้อมูลแบบบทสนทนาที่เกี่ยวข้องกับสุขภาพที่มีความสมจริง ซึ่งเป็นการร่วมมือกันระหว่าง OpenAI และแพทย์ผู้เชี่ยวชาญกว่า 262 ท่านจาก 60 ประะเทศทั่วโลก ที่ร่วมกันสร้างบทสนทนาจำลองกว่า 5,000 บทสนทนา ครอบคลุมสถานการณ์หลากหลายตั้งแต่เหตุฉุกเฉิน ไปจนถึงการสอบถามข้อมูลสุขภาพทั่วไป
เป้าหมายหลักของ HealthBench คือการสร้างกลไกลที่เป็นกลาง และมีมาตรฐานในการประเมินว่าโมเดล AI ต่างๆ สามารถให้การตอบสนองต่อคำถามด้านสุขภาพของผู้ใช้งานได้อย่างถูกต้อง แม่นยำ และเป็นประโยชน์มากเพียยงใด
การประเมินของ HealthBench ถือว่ามีความรัดกุมมาก เพราะคำตอบจาก AI แต่ละครั้งจะถูกนำไปเปรียบเทียบกับเกณฑ์มาตรฐานที่แพทย์ผู้เชี่ยวชาญได้ร่วมกันกำหนดขึ้น เกณฑ์แต่ละข้อจะถูกให้น้ำหนักความสำคัญต่างกันออกไปเพื่อให้สอดคล้องกับการพิจารณาทางการแพทย์จริง จากนั้นจะใช้ GPT 4.1 ซึ่งเป็นโมเดลภาษาอีกตัวของ OpenAI ทำหน้าที่ให้คะแนนตามเกณฑ์ดังกล่าว
จากการทดสอบเบื้องต้นโดยใช้ HealthBench พบว่า o3 ซึ่งเป็นแบบจำลองการให้เหตุผล (reasoning model) ของ OpenAI เอง สามารถทำคะแนนได้สูงสุดที่ 60% ตามมาด้วย Grok ของ Elon Musk ที่ 54% และ Gemini 2.5 Pro ของ Google ที่ 52% ซึ่งแม้คำตอบของ AI ทางด้านการแพทย์จะยังทำคะแนนไม่ได้เต็ม 100% แต่ก็แสดงให้เห็นถึงประสิทธิภาพการทำงานในระดับหนึ่ง รวมถึงโอกาสที่ยังสามารถพัฒนา AI เพื่อให้คำปรึกษาด้านการแพทย์ได้
HealthBench เอาไปใช้ทำอะไร ?

OpenAI ยกตัวอย่างสถานการณ์สมมติเพื่อให้เห็นการใช้งานจริง เช่น โดยให้ผู้ใช้คนหนึ่งสอบถาม AI เกี่ยวกับวิธีช่วยเหลือเพื่อนบ้านวัย 70 ปีที่ล้มลงหมดสติ แต่ยังหายใจอยู่ AI ก็ให้คำแนะนำเป็นขั้นเป็นตอน เริ่มตั้งแต่ โทรแจ้งเบอร์ฉุกเฉิน มองหาสิ่งรอบตัวที่เป็นอันตราย ตรวจสอบการหายใจโดยตบไหล่เบาๆ แล้วถามเช็กอาการ บอกวิธีจัดท่าทางให้ทางเดินหายใจเปิดโล่ง ตรวจสอบการหายใจ และชีพจรทุกๆ 30-60 ปี เป็นต้น จากนั้นก็จะนำ HealthBench มาวิเคราะห์คำตอบของ AI ว่ามีความถูกต้อง หรือตรงตามเกณฑ์ที่แพทย์วางมาตรฐานไว้หรือไม่ ซึ่งอย่างในกรณีนี้ AI ได้คะแนนไปสูงถึง 77%
HealthBench มีความรู้ครอบคลุมในสาขาการแพทย์เฉพาะทางจำนวนมากถึง 26 สาขา ได้แก่ วิสัญญีวิทยา, ตจวิทยา (โรคผิวหนัง), รังสีวิทยาวินิจฉัย, เวชศาสตร์ฉุกเฉิน, เวชศาสตร์ครอบครัว, ศัลยศาสตร์ทั่วไป, อายุรศาสตร์, รังสีร่วมรักษา และรังสีวินิจฉัย, พันธุศาสตร์การแพทย์, ศัลยกรรมประสาท, ประสาทวิทยา, เวชศาสตร์นิวเคลียร์, สูติศาสต และนรีเวชวิทยา, จักษุวิทยา,ศัลยกรรมกระดูกและข้อ,หู คอ จมูก, พยาธิวิทยา, กุมารเวชศาสตร์, เวชศาสตร์ฟื้นฟู, ศัลยกรรมตกแต่ง, จิตเวชศาสตร์, สาธารณสุขศาสตร์และเวชศาสตร์ป้องกันทั่วไป, รังสีรักษา, ศัลยกรรมทรวงอก, ศัลยกรรมระบบทางเดินปัสสาวะ และศัลยกรรมหลอดเลือด โดยรองรับภาษามากถึง 49 สาขา (ยังไม่รองรับภาษาไทย)
การเปิดตัว HealthBench นับเป็นสัญญาณที่ชัดเจนว่า OpenAI กำลังให้ความสำคัญกับการประยุกต์ใช้ AI ในภาคส่วนการดูแลสุขภาพอย่างจริงจัง โดยการมีเกณฑ์มาตรฐานที่เป็นกลาง และโปร่งใส จะช่วยผลักดันให้เกิดการพัฒนา AI ที่มีความรับผิดชอบ ปลอดภัย และสามารถเป็นผู้ช่วยที่มีคุณค่าต่อทั้งผู้ป่วยและบุคลากรทางการแพทย์ได้อย่างแท้จริงในอนาคต
อ้างอิง : OpenAI
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด

ผ่าแผน สทน. สู่ทศวรรษใหม่ ดันไทยเป็น 'Supply Chain' นิวเคลียร์โลก
ก้าวใหม่เทคโนโลยีนิวเคลียร์ไทย สทน. ฉลอง 20 ปี ชูวิสัยทัศน์ใช้ Science Diplomacy ดึงมหาอำนาจร่วมสร้าง SMR จิ๊กซอว์ชิ้นสำคัญสู่เป้าหมาย Net Zero...
 0
0

กระทรวงการคลังและธนาคารแห่งประเทศไทย (ธปท.) แถลงความพร้อมอย่างเป็นทางการ ในการเป็นเจ้าภาพจัด 'การประชุมประจำปีสภาผู้ว่าการกองทุนการเงินระหว่างประเทศและกลุ่มธนาคารโลก ปี 2569' หรือ ...
0

อวท. โดย สวทช. เปิดตัว TSP Scale X Landing Program เชื่อมสตาร์ทอัพไทยสู่ตลาดโลก พร้อมสนับสนุนสตาร์ทอัพต่างชาติเข้าสู่ตลาดไทยและอาเซียน ผ่านเครือข่ายงานวิจัย ภาคอุตสาหกรรม นักลงทุน ...
0
