
เข้าใจ Observability ง่าย ๆ ใน 10 นาที กับ Splunk x Opsta จากสัมมนาออนไลน์ “Unlocking the Black Box: True Observability in Action”
ในวันที่ระบบ IT ซับซ้อนขึ้นทุกวัน การมอนิเตอร์แบบเดิมอาจไม่เพียงพออีกต่อไป Splunk แบรนด์ชั้นนำด้าน Observability และ Digital Resilience ที่ก่อตั้งมาตั้งแต่ปี 2003 และปัจจุบันเป็นส่วนหนึ่งของ Cisco จึงมุ่งช่วยให้องค์กรทั่วโลกมองเห็นภาพรวมของระบบได้ครบถ้วนและเชื่อมโยงกับผลกระทบทางธุรกิจ

นี่คือที่มาของสัมมนาออนไลน์ “Unlocking the Black Box: True Observability in Action” ที่จัดขึ้นโดยความร่วมมือระหว่าง Splunk x Opsta และ Techsauce เพื่อพาผู้เข้าร่วมก้าวข้ามจาก “Monitoring” ไปสู่ “Observability” พร้อมแง่คิดและตัวอย่างจากผู้ใช้งานจริงที่เปิดโลกใหม่ของการดูแลระบบ IT
งานนี้มีผู้เข้าร่วมมากมายจากหลากหลายสายอาชีพจากทั้งองค์กรขนาดใหญ่และ Startup ที่กำลังมองหาแนวทางในการปรับปรุงระบบให้มีประสิทธิภาพและเข้าใจผู้ใช้มากขึ้น รวมถึงเหล่าพาร์ทเนอร์และลูกค้าของ Splunk และ Opsta ที่อยากอัปเดตแนวทางใหม่ ๆ ของ Observability โดยเฉพาะ
นอกจากนี้ยังได้รับเกียรติจากสองผู้เชี่ยวชาญในวงการเทคโนโลยีที่มาร่วมถ่ายทอดความรู้แบบจัดเต็ม ได้แก่
- คุณจิรายุส นิ่มแสง (คุณเดียร์) CEO และผู้ก่อตั้ง Opsta ที่มาเล่าจากประสบการณ์ตรงในการนำ Observability ไปใช้จริงในองค์กรระดับองค์กร พร้อมอธิบายแนวคิดเชิงลึกตั้งแต่ Monitoring 1.0 สู่ยุคใหม่ของ Observability 3.0 ที่เน้นผลกระทบเชิงธุรกิจมากกว่าแค่กราฟบน Dashboard
- คุณชุติมา กิจเจริญไพศาล (คุณแนน) Solutions Engineer จาก Splunk ที่มาพร้อมเครื่องมือและตัวอย่างการใช้งานจริงของ Splunk ในการทำ Observability ทั้งในระดับแอปพลิเคชัน ระบบโครงสร้างพื้นฐาน ไปจนถึงการเชื่อมโยงข้อมูลเพื่อให้เข้าใจ “ประสบการณ์ของผู้ใช้” และ “ธุรกิจ”
ทำไม Observability ถึงสำคัญ ?
คุณเดียร์ จิรายุส นิ่มแสง CEO จาก Opsta เริ่มต้นด้วยการชวนตั้งคำถามว่า “Monitoring แบบเดิม... ยังเอาอยู่ไหม?” เพราะในอดีต แค่ดู CPU, Memory หรือ uptime ก็ดูเหมือนเพียงพอแล้วสำหรับการดูแลระบบ IT แต่วันนี้ โลกเปลี่ยนไป
ระบบในยุคปัจจุบันไม่ใช่แค่ Server เครื่องเดียวอีกต่อไป แต่มักประกอบด้วยหลายองค์ประกอบ ทั้ง Container, Microservices, Cloud-native infrastructure และ User Journey ที่ซับซ้อนมากขึ้นเรื่อย ๆ ซึ่ง Monitoring แบบเดิมเน้นการมองสิ่งที่เกิดขึ้น แต่ Observability คือการทำความเข้าใจว่า ทำไมมันถึงเกิดขึ้น และ จะจัดการอย่างไร
จาก Monitoring สู่ Observability สู่ SRE วิวัฒนาการของการดูแลระบบ

คุณเดียร์สรุปวิวัฒนาการของการดูแลระบบ IT ไว้เป็น 3 ยุคหลักที่เชื่อมต่อกันได้แก่
- Monitoring คือยุคที่ระบบเน้นการเก็บทุกอย่างให้เยอะที่สุด มี Dashboard สวย ๆ แสดง CPU, RAM, IOPS ฯลฯ แต่เมื่อเกิดปัญหา ต้องไล่ดูย้อนหลังเองว่าเกิดอะไรขึ้น ยากที่จะเข้าใจประสบการณ์ผู้ใช้งานจริง
- Observability คือการเปลี่ยนจากดูทุกอย่าง เป็นดูเฉพาะสิ่งที่สำคัญ ข้อมูลหลักที่ควรโฟกัสมี 3 อย่างคือ Metrics / Logs / Traces ซึ่งจะช่วยตอบคำถามที่ Monitoring เดิมทำไม่ได้ เช่น
- ผู้ใช้งานคนนี้เจอปัญหาอะไร?
- แอปช้าตรงไหน?
- มีจุดใดที่ Transaction ติดค้าง?
ดังนั้นการ Observability ไม่ได้แค่แสดงผล แต่ช่วยให้ทีมเข้าใจปัญหาเชิงลึก และจัดลำดับความสำคัญในการแก้ไขได้
- SRE (Site Reliability Engineering) คือการยกระดับจากการดูและแก้ ไปสู่การออกแบบระบบให้เสถียร ตั้ง SLO (Service Level Objective) ให้ชัด ซึ่งช่วยให้ทีม DevOps ทำงานอย่างเป็นระบบ
จาก Data สู่ Insight องค์ประกอบหลักของ Observability
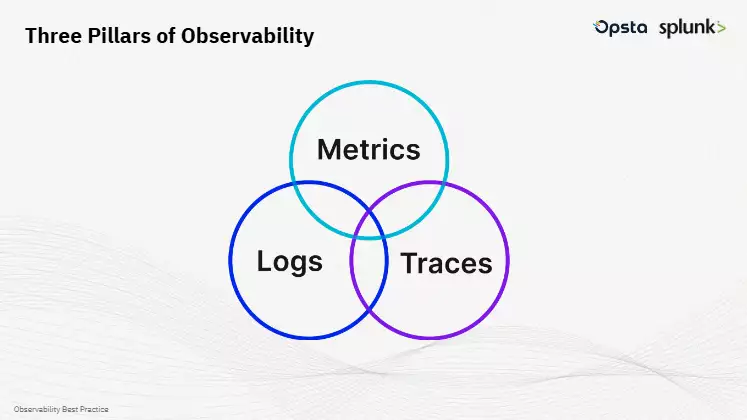
หนึ่งในหัวใจสำคัญที่คุณเดียร์จาก Opsta เน้นย้ำตลอดเซสชันคือ Observability ที่มีประสิทธิภาพต้องประกอบด้วยข้อมูลหลัก 3 ประเภท ได้แก่ Metrics, Logs และ Traces ซึ่งแต่ละแบบต่างก็มีบทบาทของตัวเอง
- Metrics คือข้อมูลเชิงตัวเลขที่เราใช้กันอยู่ทั่วไป เช่น ปริมาณการใช้ CPU, memory, หรือจำนวน request ที่เข้ามาในระบบ ข้อมูลแบบนี้มักจะเบา เก็บได้นาน และนิยมนำมาทำกราฟเพื่อดูแนวโน้ม
- Logs คือข้อความที่ระบบเขียนบันทึกไว้ในระหว่างทำงาน เช่น ข้อความที่บอกว่า user login สำเร็จ หรือ connection timeout ข้อมูลแบบนี้ใช้ในการสืบย้อนว่าระบบทำอะไรไปบ้าง และมี error เกิดขึ้นที่จุดไหน
- Traces นั้นจะเป็นเหมือนแผนที่ หรือเส้นทางของ request แต่ละคำสั่ง ว่าผ่านระบบไหนบ้าง ใช้เวลาตรงไหนนาน หรือสะดุดอยู่ที่จุดใด ซึ่งเหมาะมากกับการวิเคราะห์ระบบที่ซับซ้อน เช่น microservices หรือ containerized apps
สิ่งที่องค์กรควรเข้าใจคือ ข้อมูลทั้ง 3 ประเภทนี้ กินพื้นที่ไม่เท่ากัน Metrics นั้นเล็กและเบา เก็บได้ยาวนานอย่างไม่ลำบาก แต่ Logs และ Traces นั้น “หนักมาก” หากเก็บโดยไม่คัดกรอง จะเปลืองทรัพยากรเกินความจำเป็น ดังนั้นแนวทางที่ดีที่สุดคือ การเก็บเฉพาะข้อมูลที่มีประโยชน์ ต่อการใช้งานจริง
Best Practices ที่ต้องรู้
- ออกแบบระบบให้ Log ข้อมูลในรูปแบบที่อ่านและวิเคราะห์ได้ง่าย แทนที่จะเป็นข้อความธรรมดา ๆ ซึ่งมักจะอ่านยากและค้นหาข้อมูลลำบาก ระบบที่มี log format ดีจะช่วยให้การสืบค้นปัญหาทำได้รวดเร็วและอัตโนมัติมากขึ้น เช่น JSON หรือ structured log format
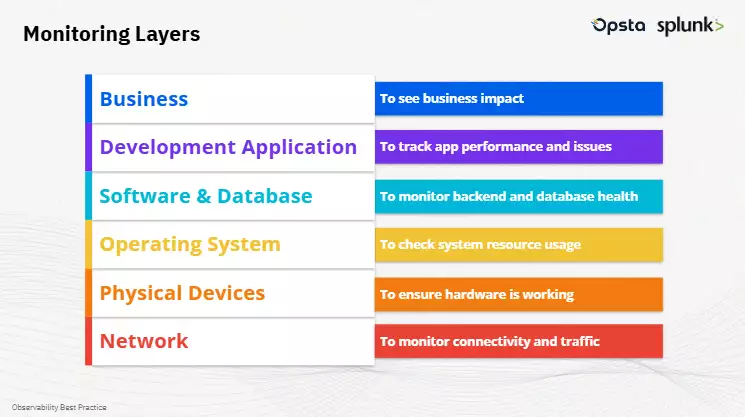
- การแยกการ Monitoring ออกเป็นหลาย Layer เช่น Infra, Network, Application และ Business เพราะแต่ละ Layer มีภาระหน้าที่ที่ต่างกัน ปัญหาในระบบอาจไม่ใช่แค่เรื่องเทคนิคอย่าง CPU เต็ม แต่อาจกระทบกับประสบการณ์ของผู้ใช้งานหรือยอดขายของธุรกิจโดยตรง การเข้าใจว่าปัญหาอยู่ที่ Layer ไหนจึงสำคัญต่อการแก้ไขอย่างมีทิศทาง
- สูตรการมองระบบ 2 แบบ ที่ช่วยให้ทีมเข้าใจภาพได้ครบถ้วน สูตรแรกคือ RED (Request – Error – Duration) สูตรนี้ใช้ “มองจากฝั่งผู้ใช้งาน” ว่าประสบการณ์ของเขาดีแค่ไหน เช่น มีผู้ใช้เข้าเว็บเยอะ แต่กลับเจอ error หรือโหลดช้า อันนี้คือสัญญาณว่ามีปัญหาในฝั่งที่ user รู้สึกได้จริง, สูตรที่สองคือ USE (Utilization – Saturation – Error) สูตรนี้ใช้ดูว่าระบบภายในเริ่มหนักหรือเสี่ยงจะพังตรงจุดไหน
- แนวคิดเรื่องการตั้ง Alert ที่มีเป้าหมายทางธุรกิจ คุณเดียร์ย้ำว่า เราไม่ควรตั้งระบบเตือนทุกครั้งที่ CPU แตะ 85% หรือ RAM สูงเกิน 90% เพราะถ้าในขณะนั้นผู้ใช้งานยังสามารถเข้าแอปได้ปกติ ไม่มีปัญหาอะไรเกิดขึ้นจริง การแจ้งเตือนแบบนี้อาจกลายเป็น “เสียงรบกวน” แทนที่จะช่วยให้ทีมเห็นปัญหาที่แท้จริง
Observability 3.0 จากข้อมูลเทคนิค สู่ข้อมูลธุรกิจ
คุณเดียร์สรุปบทเรียนว่า เรากำลังเข้าสู่ยุคของ Observability 3.0 แล้ว ซึ่งต่างจากยุคแรก ๆ ที่แค่ดูกราฟกับ Log
- Observability 1.0 ใช้เครื่องมือแยกกัน เก็บข้อมูลไม่สัมพันธ์กัน
- Observability 2.0 รวมข้อมูลไว้ในที่เดียว สร้างความสัมพันธ์ระหว่าง Metrics / Logs / Traces
- Observability 3.0 โฟกัสที่ User Experience และ Business Impact
“ระบบล่มไม่ใช่แค่เรื่องของ Dev แล้ว แต่คือเรื่องของ CEO, CMO และลูกค้า” ดังนั้น Observability ที่ดีต้องตอบให้ได้ว่า “ระบบที่ล่ม กระทบธุรกิจแค่ไหน และเรารู้ล่วงหน้าไหมว่ามันจะล่ม”
Splunk กับการสร้าง Observability ที่เห็นทั้งระบบ
หลังจากคุณเดียร์จาก Opsta ปูพื้นฐานเรื่องแนวคิด Observability อย่างเต็มอิ่มแล้ว เซสชันถัดมาคือมุมมองของ คุณแนน Solutions Engineer จาก Splunk ที่พาเราก้าวข้ามจากแนวคิด มาสู่การลงมือทำจริงผ่านเครื่องมือที่สามารถสร้าง Observability แบบครบวงจร
คุณแนนเริ่มจากปัญหาที่ทุกคนคุ้นเคย คือ แต่ละทีมในองค์กรมีเครื่องมือของตัวเอง เช่น ทีม Network ใช้ Tool หนึ่ง, ทีม Infra ใช้อีก Tool, ทีมแอปใช้ Tool ของตัวเอง ทำให้เวลาเกิดปัญหา ไม่สามารถเชื่อมโยงข้อมูลข้ามทีมได้ การตามหา root cause จึงกลายเป็นภารกิจงมเข็มในมหาสมุทรทุกครั้ง เพราะข้อมูลกระจัดกระจาย ไม่มีศูนย์กลางเดียว
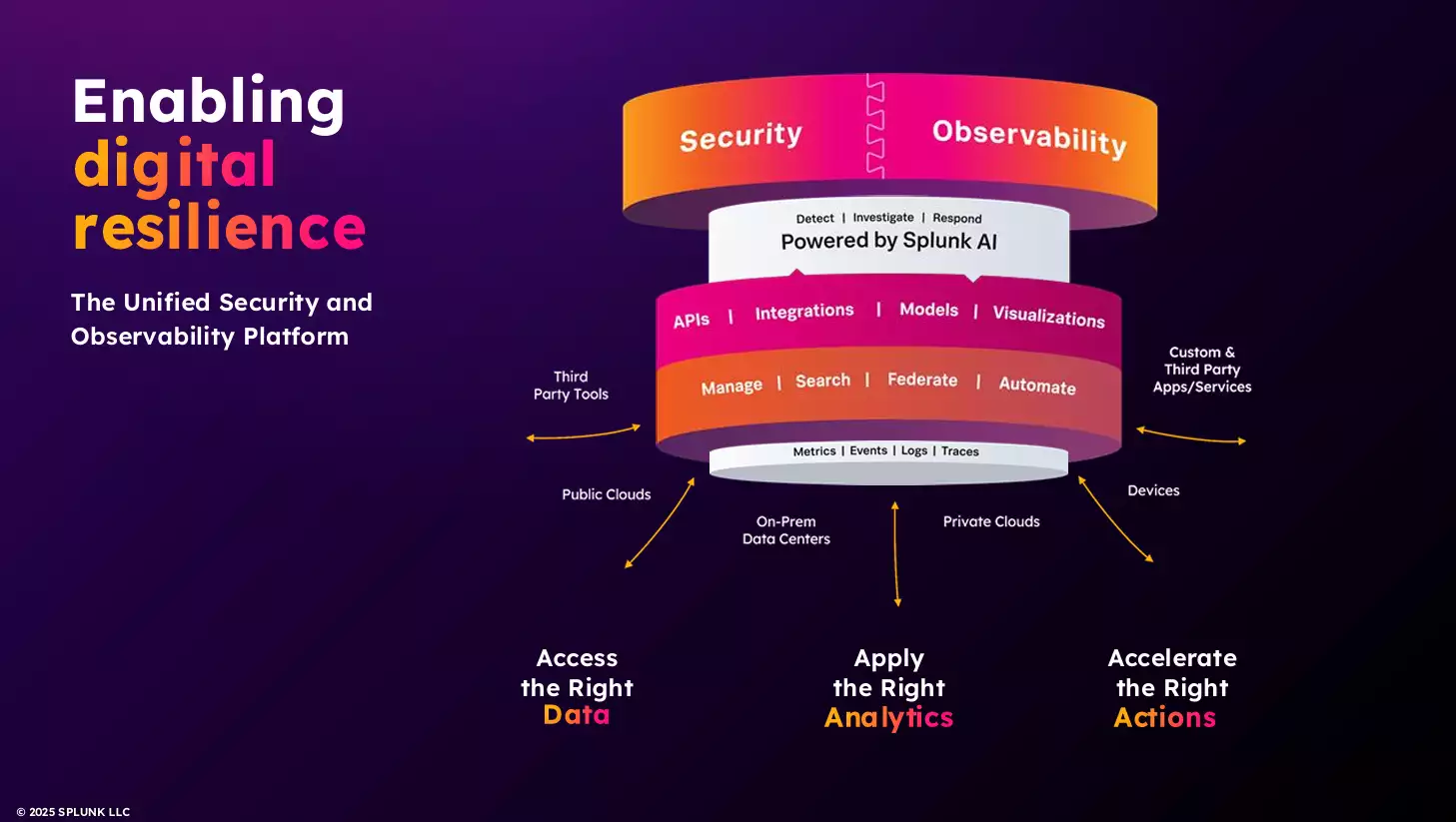
ดังนั้น สิ่งที่ Splunk Observability ทำ คือ การเป็นแพลตฟอร์มที่ไม่ได้เน้นแค่การเก็บข้อมูลหรือดูแลระบบ แต่คือการ “เชื่อมโยงข้อมูลทุกระดับ” ทั้ง Infrastructure, Application, Network, Security ไปจนถึง Experience ของผู้ใช้ และ Business Health ทั้งหมดนี้ทำให้ทีมสามารถ “มองเห็นภาพรวมของระบบอย่างแท้จริง” (End-to-End Visibility)
โมดูลหลักของ Splunk Observability มีอะไรบ้าง ?
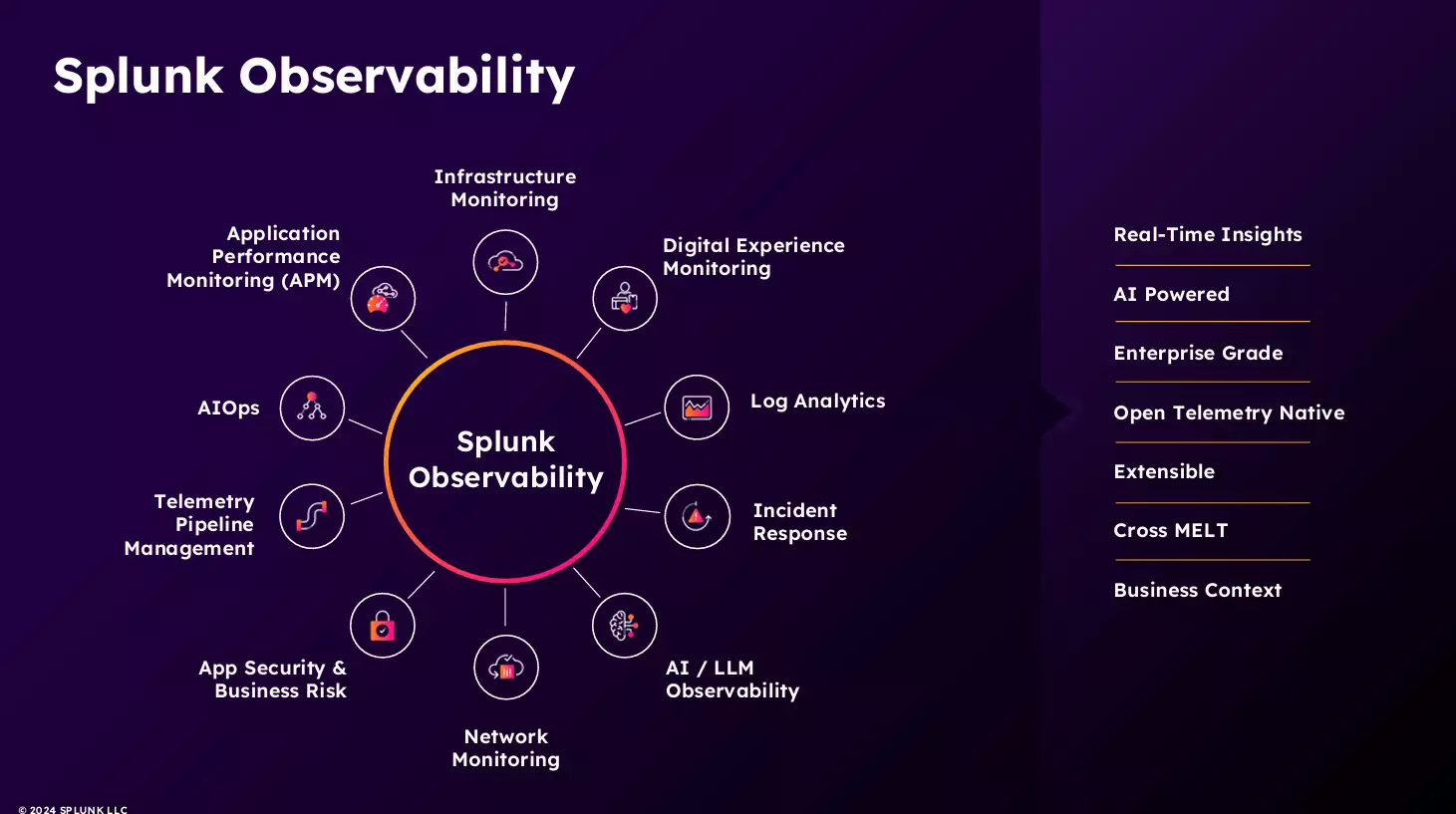
หนึ่งในจุดเด่นของ Splunk ที่คุณแนนจากทีม Solutions Engineer ได้อธิบายไว้อย่างชัดเจนก็คือ การรวมเอาความสามารถด้าน Observability หลายมิติไว้ในแพลตฟอร์มเดียว ไม่ว่าจะเป็นมุมมองจากโครงสร้างพื้นฐาน (Infrastructure) ประสบการณ์ของผู้ใช้ (User Experience) ไปจนถึงระดับแอปพลิเคชัน (Application Monitoring)
จากภาพประกอบจะเห็นว่า Splunk Observability มีโมดูลหลักมากถึง 10 ส่วนที่เชื่อมโยงกันอย่างเป็นระบบ อาทิ
- Infrastructure Monitoring ช่วยติดตามสถานะของเซิร์ฟเวอร์, Container, Cloud Infrastructure แบบ Real-time
- Application Performance Monitoring (APM) มอนิเตอร์การทำงานของแอปพลิเคชันในระดับ service และ microservices
- Digital Experience Monitoring (DEM) มอนิเตอร์ประสบการณ์ของผู้ใช้จริง (ผ่าน Real User Monitoring หรือ RUM)
- Log Analytics วิเคราะห์ log ปริมาณมหาศาลจากทุกระบบ ทั้ง infra, app, network ฯลฯ พร้อมจัดกลุ่มและเชื่อมโยงความสัมพันธ์ให้เห็นว่าปัญหาเริ่มจากตรงไหน และกระทบระบบอื่นยังไง
- Incident Response ผสานกับระบบแจ้งเตือนและจัดการเหตุการณ์ (Incident Management) เพื่อให้ทีม SRE หรือ DevOps สามารถรับมือปัญหาได้ทันที พร้อมตรวจสอบ root cause อย่างมีประสิทธิภาพ
- AI / LLM Observability รองรับการมอนิเตอร์และวิเคราะห์ระบบ AI โดยเฉพาะ เช่น ตรวจสอบพฤติกรรม LLM หรือ Machine Learning Model, Latency, Data Drift และผลลัพธ์ที่ไม่คาดคิดจากโมเดล
- Network Monitoring วิเคราะห์การเชื่อมต่อระหว่างระบบ เช่น latency, throughput และ error บนเครือข่าย ซึ่งสำคัญมากในยุคที่ระบบแอปพลิเคชันกระจายอยู่หลายที่
- App Security & Business Risk ผสานข้อมูลจากฝั่ง security เข้ามา
- Telemetry Pipeline Management จัดการ “ท่อส่งข้อมูล” ให้ระบบทั้งหมดขององค์กรสามารถส่ง Metrics, Logs, Traces เข้าสู่ Splunk ได้อย่างมีประสิทธิภาพ ไม่ต้องเขียนเองจากศูนย์
AIOps ใช้ AI วิเคราะห์ข้อมูลย้อนหลังจำนวนมาก เพื่อทำนายปัญหาที่อาจเกิดขึ้นล่วงหน้า และช่วยลด noise จาก alert ที่ไม่จำเป็น
ใช้งานง่ายด้วย AI Assistant for Observability
หนึ่งในไฮไลต์สำคัญของ Splunk Observability คือการเสริมความสามารถด้วย AI Assistant ที่ออกแบบมาเพื่อช่วยให้ทีม IT, DevOps และ SRE ทำงานได้เร็วขึ้น ฉลาดขึ้น และแม่นยำยิ่งขึ้น โดยใช้เพียงแค่ “ภาษาพูดธรรมดา” ไม่ต้องเขียนโค้ด ไม่ต้องจมอยู่กับ Dashboard หลายสิบหน้า
AI Assistant ใน Splunk ช่วยให้ผู้ใช้งานสามารถพิมพ์คำถามในรูปแบบภาษาธรรมชาติ เช่น:
- “ทำไม microservice payments ถึงมี error เพิ่มขึ้น?”
- “มีเหตุการณ์อะไรเกิดขึ้นก่อนที่ checkout จะล่ม?”
- “แสดงบริการ upstream ที่เกี่ยวข้องกับระบบ login ให้หน่อย”
ระบบจะประมวลผลคำถามเหล่านี้ และเชื่อมโยงข้อมูลจากหลายแหล่ง ทั้ง metric, log, trace, event และ dependency map แล้วตอบกลับด้วย Insight ที่อธิบายเข้าใจง่าย พร้อมทางเลือก หรือแนวทางแก้ไขที่สามารถคลิกดูต่อได้ทันที
Glass Tables เห็นภาพระบบทั้งหมดแบบ End-to-End
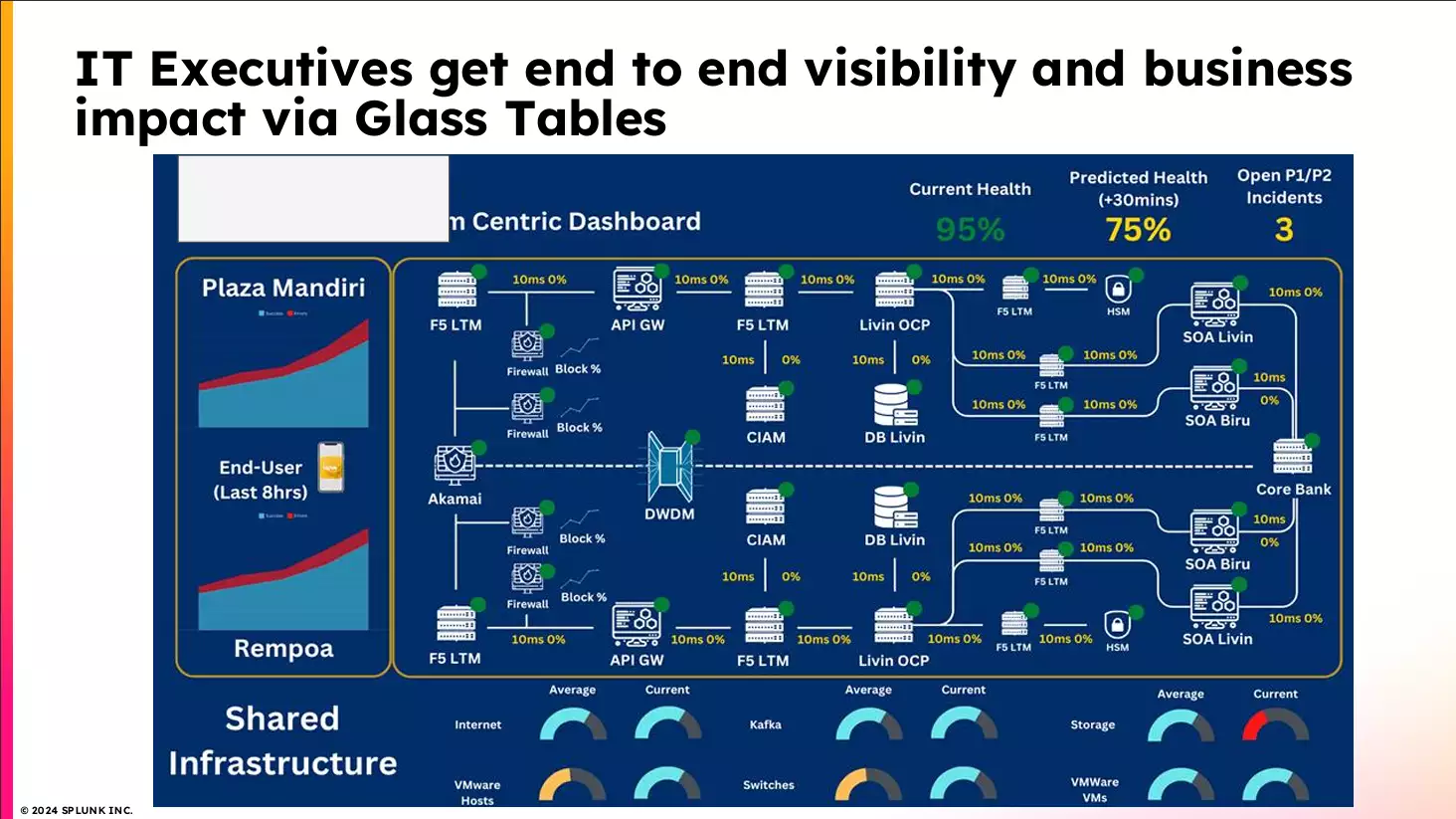
หนึ่งในเครื่องมือที่ทรงพลังที่สุดของ Splunk คือ Glass Table เป็นแดชบอร์ดแบบ visual ที่แสดงความเชื่อมโยงของระบบทั้งหมด ตั้งแต่โครงสร้างพื้นฐาน, แอปพลิเคชัน, ไปจนถึงประสบการณ์ของผู้ใช้งานจริง ๆ ในแบบ end-to-end ทั้งในมุมของ IT และธุรกิจ
ยกตัวอย่างเช่น เมื่อระบบบางส่วนล่ม Glass Table จะช่วยบอกทันทีว่าเกิดขึ้นตรงไหน, มี service ไหนได้รับผลกระทบ, และสิ่งนี้สัมพันธ์กับ business metric เช่น conversion rate หรือลูกค้า login ไม่ได้อย่างไร แถมยังแสดง “สุขภาพของระบบในอนาคต” ว่ามีแนวโน้มจะมี incident หรือไม่ ด้วย predicted health และแสดงจำนวนเหตุการณ์ที่ต้องจัดการ เช่น P1/P2 incidents
ความพิเศษคือ Glass Tables ออกแบบให้ผู้บริหารหรือ IT Executive เข้าใจได้ทันที โดยไม่ต้องลงลึกในเชิงเทคนิค แต่สามารถใช้ตัดสินใจได้เลยว่าควรเร่งแก้จุดไหนก่อน หรือส่งทีมไหนเข้าไปจัดการ
ในวันที่ระบบ IT กลายเป็น “กล่องดำ” ที่ซับซ้อนเกินกว่าจะมองเห็นแค่ผ่าน Dashboard ธรรมดา งานสัมมนาออนไลน์ “Unlocking the Black Box: True Observability in Action” จึงเป็นเวทีสำคัญที่เปิดโลกของ Observability ให้เข้าใจง่าย ใช้งานได้จริง และเห็นผลกระทบต่อธุรกิจ
ทั้งจากมุมมองแนวคิดลึก ๆ โดยคุณจิรายุส นิ่มแสง (CEO – Opsta) ไปจนถึงโซลูชันระดับองค์กรที่ใช้ได้ทันทีจากคุณชุติมา กิจเจริญไพศาล (Solutions Engineer – Splunk) ผู้เข้าร่วมได้เห็นว่า Observability ไม่ใช่แค่เรื่องของเครื่องมือ แต่คือวิธีคิดใหม่ในการดูแลระบบให้ไม่เพียงพร้อมใช้งาน แต่พร้อมเข้าใจไปพร้อมกัน
สำหรับใครที่สนใจติดตามงานสัมมนาดี ๆ แบบนี้อีก สามารถติดตามได้ที่: https://www.splunk.com/en_us/products/observability.html
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด

3 เทรนด์ชี้ชะตาธุรกิจโลก: สรุปเวที Summer Davos (AI - พลังงาน - ยุทธศาสตร์จีน) | Tech for Biz EP.62
สรุป Summer Davos Techsauce สรุปประเด็นร้อนที่ส่งตรงจาก Congress Hall ใน Dalian กับ 3 จุดเปลี่ยนที่ธุรกิจไทยต้องรีบปรับตัว...
 0
0

โอกาสของไทยในฐานะเจ้าภาพ "โอลิมปิกการเงินโลก" (IMF-World Bank 2026) ครั้งที่ 2 ในรอบ 35 ปี ถอดบทเรียนจาก 3 ประเทศเจ้าภาพ งานจบแล้วเราจะได้อะไร?...
0

สัมภาษณ์พิเศษ ดร.กริชผกา บุญเฟื่อง ไขทุกคำถามเรื่องกลไกร่วมทุนสตาร์ทอัพของ NIA
Techsauce เคยรายงานข่าวไปแล้วว่า NIA สามารถลงทุนในสตาร์ทอัพได้ วันนี้เราพา ดร.กริชผกา บุญเฟื่อง ผู้อำนวยการ NIA มาอธิบายรายละเอียดแบบเต็ม ๆ ว่ากลไกใหม่นี้ทำงานอย่างไร...
0
