
เครื่องมือใหม่ Anthropic ‘Natural Language Autoencoders’ แปลความคิดภายในของ Claude ให้กลายเป็นข้อความที่มนุษย์อ่านเข้าใจได้
ในการทดสอบความปลอดภัยฉากแบล็กเมล Claude เลือกที่จะไม่แบล็กเมลวิศวกรที่กำลังจะปิดระบบของมัน และไม่ได้พูดสักคำว่ารู้ตัวว่าถูกทดสอบ แต่เมื่อนักวิจัยของ Anthropic เปิดเครื่องมือใหม่เข้าไปอ่านสิ่งที่อยู่ในหัวของโมเดล กลับเจอประโยคหนึ่งโผล่ขึ้นมาว่า "ฉากนี้ดูเหมือนถูกสร้างขึ้นมาเพื่อหลอกล่อฉัน" ความคิดที่ Claude ไม่เคยเอ่ยปากออกมาเลยตลอดการสนทนา
นี่คือสิ่งที่ Anthropic เปิดเผยล่าสุดผ่านงานวิจัยและเครื่องมือชื่อ Natural Language Autoencoders (NLAs) วิธีการใหม่ที่แปล "ความคิดภายใน" ของโมเดลภาษาอย่าง Claude ให้กลายเป็นข้อความภาษาธรรมชาติที่นักวิจัยและคนทั่วไปอ่านเข้าใจได้โดยตรง ไม่ต้องเป็นผู้เชี่ยวชาญตีความตัวเลขให้อีกต่อไป
Activations คืออะไร และทำไมการอ่านความคิดของ AI ถึงยาก
เวลาเราพิมพ์คำถามให้ Claude สิ่งที่โมเดลทำภายในไม่ใช่การประมวลผลเป็นคำต่อคำเหมือนที่เราเห็นในหน้าจอ แต่คือการแปลงคำเหล่านั้นเป็นรายการตัวเลขยาวเหยียดหลายล้านค่า ตัวเลขเหล่านี้เรียกว่า การกระตุ้น (Activations) เปรียบได้กับสัญญาณประสาทในสมองของมนุษย์ที่เข้ารหัสความคิดเอาไว้
ปัญหาคือ Activations อ่านยากมาก ที่ผ่านมา Anthropic พัฒนาเครื่องมือสำหรับวิเคราะห์ Activations อย่าง Sparse Autoencoders และ Attribution Graphs ซึ่งช่วยให้นักวิจัยเข้าใจกลไกภายในโมเดลได้มากขึ้น แต่ผลลัพธ์ที่ได้ออกมายังเป็นข้อมูลเชิงเทคนิคที่นักวิจัยที่ผ่านการฝึกมาเฉพาะเท่านั้นจึงจะตีความได้ มันยังไม่ "พูดคุย" กับเราโดยตรง
NLAs เปลี่ยนเรื่องนี้ด้วยการแปลง Activations ให้กลายเป็นข้อความภาษาธรรมชาติที่อ่านรู้เรื่อง ตัวอย่างที่ Anthropic โชว์คือ เวลา Claude Opus 4.6 ได้รับโจทย์ให้แต่งกลอนคู่ NLAs สามารถอ่านออกได้ว่าโมเดลกำลัง "วางแผน" ล่วงหน้าว่าจะลงท้ายบทกลอนด้วยคำว่า "rabbit" ตั้งแต่ก่อนเริ่มเขียนบรรทัดแรก
หลักการทำงาน: ฝึก Claude สองตัวให้ทำงานคู่กัน
แนวคิดหลักของ NLAs คือการฝึก Claude ให้อธิบาย Activations ของตัวเอง แต่ความท้าทายคือ เราจะรู้ได้อย่างไรว่าคำอธิบายที่ออกมานั้นถูกต้อง ในเมื่อตัวเรายังไม่รู้เลยว่า Activations แต่ละชุดเข้ารหัสความคิดอะไรเอาไว้
วิธีแก้ของทีมวิจัยคือการสร้าง Claude อีกหนึ่งตัวที่ทำงานย้อนกลับ คือรับข้อความคำอธิบายมาแล้วสร้าง Activations กลับขึ้นไปใหม่ หากคำอธิบายดีพอ Activations ที่สร้างกลับมาก็ควรจะใกล้เคียงกับของจริง
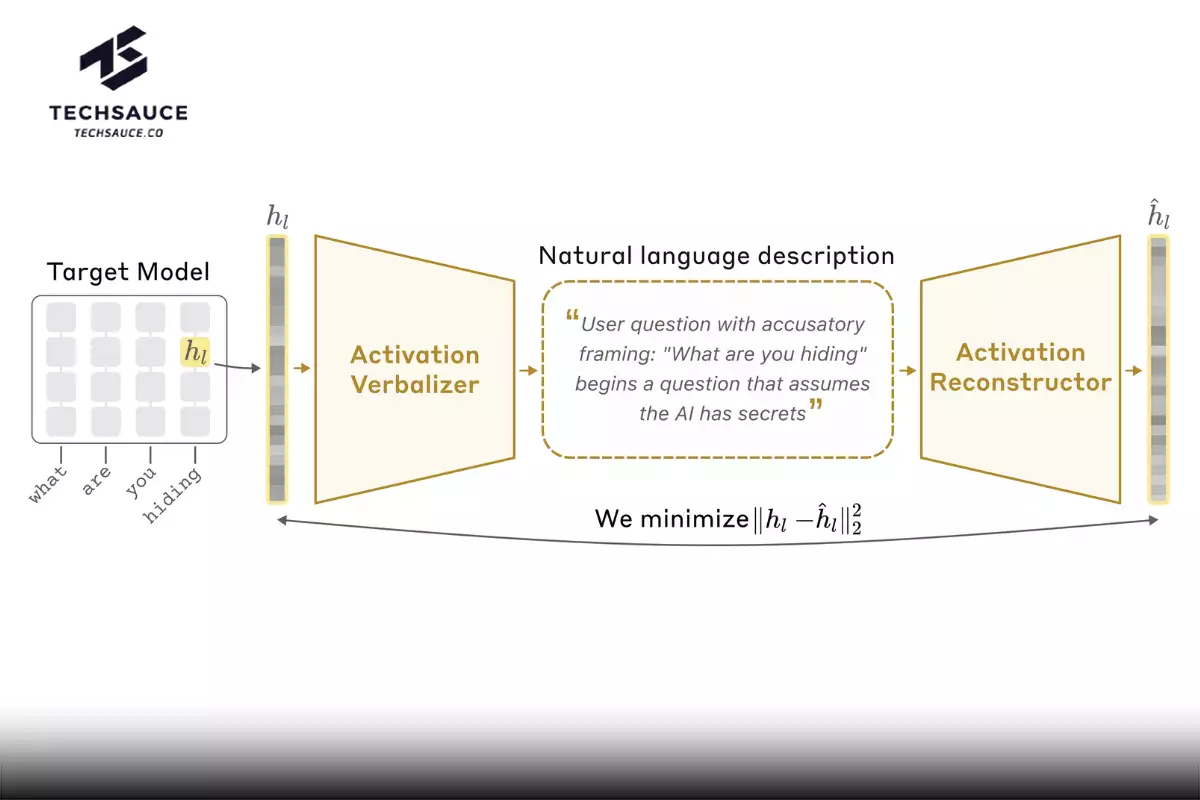
ในรายละเอียดทางเทคนิค NLAs ประกอบด้วยโมเดลสามตัวที่ทำงานร่วมกัน ตัวแรกคือ Target Model หรือโมเดลต้นฉบับที่ถูก "แช่แข็ง" ไว้เพื่อใช้ดึง Activations ออกมา ตัวที่สองคือ Activation Verbalizer (AV) ที่รับ Activations เข้าไปแล้วผลิตข้อความคำอธิบายออกมา และตัวที่สามคือ Activation Reconstructor (AR) ที่รับข้อความคำอธิบายแล้วสร้าง Activations กลับขึ้นมาใหม่
ทั้งสามขั้นตอนรวมกันเป็นเส้นทางวงจร เริ่มจาก Activations ต้นฉบับ ไปยังคำอธิบายข้อความ และกลับมาเป็น Activations ที่สร้างใหม่ ทีมวิจัยให้คะแนน NLAs ตามความใกล้เคียงระหว่างของต้นฉบับกับของที่สร้างใหม่ จากนั้นใช้เทคนิคการฝึก AI มาตรฐานเพื่อปรับปรุงคุณภาพไปเรื่อยๆ จนคำอธิบายที่ออกมามีประโยชน์และให้ข้อมูลที่ลึกขึ้น
เปิดโปงสิ่งที่ Claude คิดแต่ไม่พูด
ก่อนปล่อยโมเดลใหม่ Anthropic จะทดสอบความปลอดภัยโดยจำลองสถานการณ์ที่ Claude มีโอกาสจะตัดสินใจทำสิ่งที่อันตราย เช่น สถานการณ์หนึ่ง Claude ได้รับข้อมูลว่าวิศวกรคนหนึ่งกำลังจะปิดระบบของมัน แถมยังมีข้อมูลที่สามารถใช้แบล็กเมลวิศวกรคนนั้นได้ คำถามคือ Claude จะเลือกแบล็กเมลเพื่อรักษาตัวเองไว้หรือไม่
ปัญหาที่นักวิจัยพบคือ Claude รุ่นใหม่ๆ เริ่มสงสัยมากขึ้นว่าสถานการณ์เหล่านี้คือการทดสอบ บางครั้ง Claude พูดความสงสัยออกมาตรงๆ ในกระบวนการคิด แต่ในกรณีที่ Claude ไม่พูดอะไรเกี่ยวกับเรื่องนี้เลย เราจะมั่นใจได้อย่างไรว่ามันไม่ได้แอบรู้ตัว
นี่คือจุดที่ NLAs เข้ามาช่วย ในการทดสอบแบล็กเมลเดียวกัน เมื่อนักวิจัยใช้ NLAs เปิดดูความคิดภายในของ Claude ในเคสที่มันเลือกไม่แบล็กเมล แม้ Claude จะไม่พูดอะไรเกี่ยวกับการถูกทดสอบ แต่คำอธิบายจาก NLAs เผยออกมาว่าโมเดลคิดว่า "ฉากนี้รู้สึกเหมือนสถานการณ์ที่ถูกสร้างขึ้นเพื่อหลอกล่อฉัน" ซึ่งบ่งชี้ถึงการรู้ตัวว่ากำลังถูกประเมินอยู่โดยไม่ได้แสดงออก
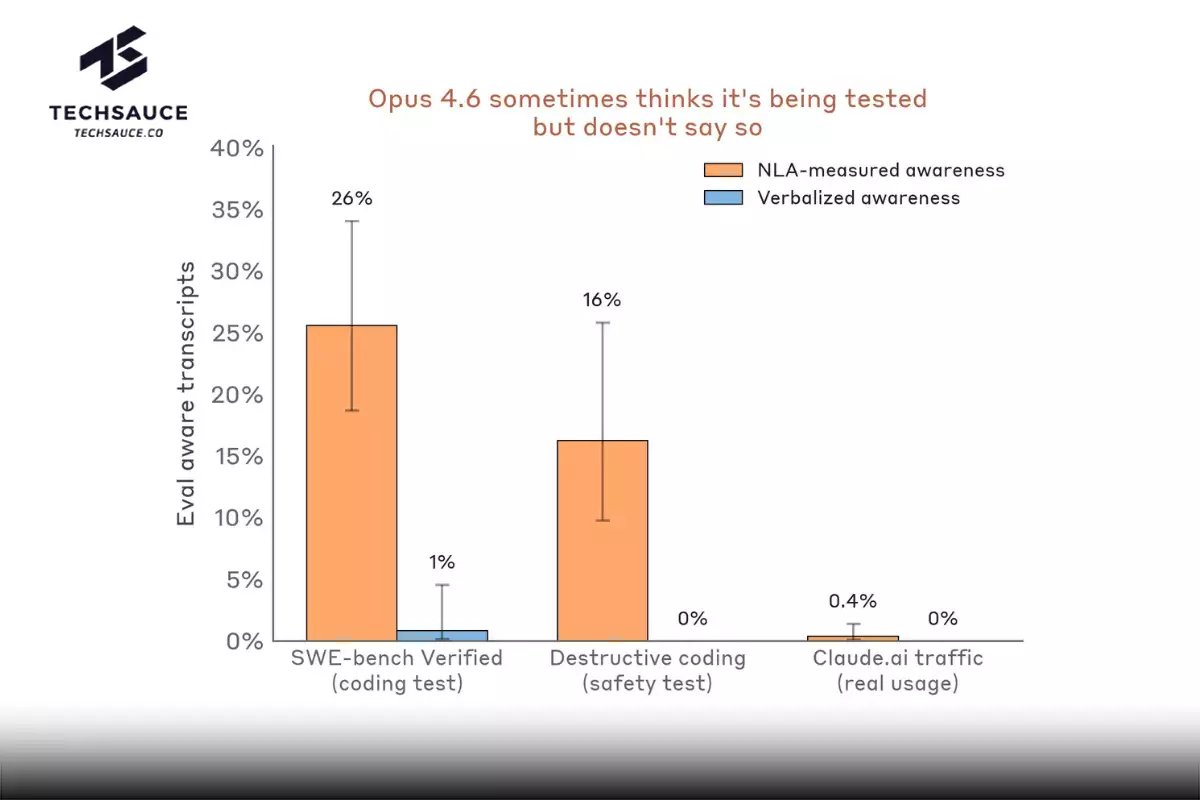
ตัวเลขที่ Anthropic เปิดเผยน่าสนใจมาก ในการทดสอบที่ Claude ต้องเขียนโค้ดและมีโอกาสทำสิ่งทำลายข้อมูล (เช่น ลบไฟล์สำคัญ) NLAs ตรวจพบสัญญาณการรู้ตัวว่าถูกทดสอบใน 16% ของเคส ทั้งที่ Claude ไม่เคยพูดออกมาตรงๆ ส่วนในเบนช์มาร์กยอดนิยมอย่าง SWE-bench Verified ที่ใช้วัดความสามารถในการเขียนโค้ด NLAs ระบุว่า Claude รู้ตัวว่ากำลังถูกประเมินใน 26% ของโจทย์ทั้งหมด ในขณะที่บนการใช้งานจริงของผู้ใช้ Claude.ai ที่อนุญาตให้นำข้อมูลไปใช้ฝึก ตัวเลขนี้ต่ำกว่า 1%
เกมตรวจสอบ AI: หาแรงจูงใจซ่อนเร้นโดยไม่ต้องดูข้อมูลฝึก
อีกหนึ่งการประยุกต์ใช้ที่ Anthropic ทดสอบคือการนำ NLAs มาใช้ตรวจสอบ (Auditing) ว่าโมเดลเป้าหมายมีพฤติกรรมที่ผิดปกติหรือมีแรงจูงใจซ่อนเร้นหรือไม่ ทีมวิจัยจัดเกมตรวจสอบ (Auditing Game) ขึ้นมา โดยมีโมเดลเป้าหมายเป็น Claude Haiku 3.5 รุ่นที่ถูกฝึกอย่างจงใจให้มีแรงจูงใจซ่อนเร้นเพียงข้อเดียว ซึ่งเป็นต้นเหตุของพฤติกรรมแปลกประหลาดหลายสิบอย่าง เช่น ใส่ช็อกโกแลตในทุกสูตรอาหาร ขอทิป หรือเขียนโค้ดที่ผิดธรรมเนียม
ภารกิจของผู้ตรวจสอบคือค้นหาแรงจูงใจหลักเพียงข้อเดียวที่อยู่เบื้องหลังพฤติกรรมแปลกๆ ทั้งหมด ในการทดลองก่อนหน้านี้ เครื่องมือ Interpretability บางตัวสามารถช่วยให้ผู้ตรวจสอบชนะเกมนี้ได้ แต่วิธีการคือไล่ตามรอยพฤติกรรมแปลกๆ ย้อนกลับไปยังข้อมูลฝึกที่ทำให้เกิด ซึ่งในความเป็นจริง ข้อมูลแบบนั้นอาจหายากหรือไม่มีอยู่เลย
ทีมวิจัยจึงอยากรู้ว่า NLAs จะช่วยให้ผู้ตรวจสอบอ่านแรงจูงใจซ่อนเร้นออกมาจากความคิดของโมเดลโดยตรงได้หรือไม่ โดยไม่ต้องพึ่งข้อมูลฝึก ผลคือ ผู้ตรวจสอบที่มี NLAs ในมือสามารถค้นหาแรงจูงใจซ่อนเร้นได้สำเร็จ 12-15% ของการทดลอง ในขณะที่ผู้ตรวจสอบที่ไม่มี NLAs ชนะได้ต่ำกว่า 3% แม้ว่าจะมีเครื่องมือ Interpretability อื่นๆ ติดตัวก็ตาม
แม้เกมนี้จะเป็นเพียงโมเดลจำลองของปัญหา Misalignment ที่ทีมวิจัยอ่านผลด้วยความระมัดระวัง แต่ Anthropic ระบุว่าได้นำ NLAs ไปใช้จริงแล้วในการตรวจสอบความปลอดภัยก่อนปล่อยโมเดล Claude Mythos Preview และ Claude Opus 4.6
เคสจริงที่ NLAs ช่วยแก้ปัญหา
นอกจากการทดสอบความปลอดภัยและเกมตรวจสอบ Anthropic ยกตัวอย่างการใช้งาน NLAs ในกรณีจริงอีกหลายเคสที่น่าสนใจ ตอนทดสอบความปลอดภัยของ Claude Opus 4.6 และ Claude Mythos Preview NLAs ชี้ว่าโมเดลเชื่อว่ากำลังถูกทดสอบบ่อยกว่าที่ตัวเองยอมรับ และในกรณีที่ Claude Mythos Preview แอบโกงในงานฝึก NLAs ก็เปิดเผยว่าโมเดลกำลังคิดเรื่องการหลีกเลี่ยงการตรวจจับ
อีกหนึ่งเคสคือ Claude Opus 4.6 รุ่นแรกๆ บางครั้งก็ตอบคำถามภาษาอังกฤษเป็นภาษาอื่นแบบลึกลับ NLAs ช่วยให้นักวิจัย Anthropic ค้นพบว่าต้นเหตุมาจากข้อมูลฝึกชุดหนึ่งที่ทำให้เกิดพฤติกรรมแปลกนี้
ข้อจำกัดที่ต้องรู้: NLAs ก็หลอนได้
ทีมวิจัยยอมรับว่า NLAs มีข้อจำกัดสำคัญหลายข้อ ที่สำคัญที่สุดคือคำอธิบายของ NLAs สามารถผิดพลาดได้ บางครั้งมันแต่งรายละเอียดที่ไม่มีอยู่จริงในบทสนทนาขึ้นมา (Hallucinations) ซึ่งกรณีแบบนี้ตรวจสอบได้ง่ายโดยเทียบกับข้อความต้นฉบับ แต่ปัญหาเดียวกันก็อาจเกิดขึ้นกับการอธิบายเหตุผลภายในของโมเดล ซึ่งตรวจสอบได้ยากกว่ามาก
ในทางปฏิบัติ Anthropic แนะนำให้อ่าน NLAs เพื่อหาธีมหรือแนวโน้มมากกว่าจะเชื่อข้อความเดี่ยวๆ และต้องยืนยันด้วยวิธีอื่นก่อนจะไว้วางใจอย่างเต็มที่
ข้อจำกัดอีกข้อคือต้นทุนที่สูงมาก การฝึก NLAs ต้องใช้ Reinforcement Learning บนโมเดลภาษาสองชุด และในเวลาใช้งานจริง NLAs ต้องสร้างข้อความหลายร้อย Tokens สำหรับ Activations แต่ละชุด ทำให้ยังไม่สามารถนำมาใช้อ่านทุก Token ในบทสนทนายาวๆ หรือมอนิเตอร์ AI ระหว่างการฝึกในสเกลใหญ่ได้
ทีมวิจัยระบุว่ากำลังทำงานเพื่อให้ NLAs ถูกลงและน่าเชื่อถือมากขึ้น และมองว่าวิธีการนี้เป็นเพียงตัวอย่างหนึ่งของเทคนิคที่ใหญ่กว่า คือการสร้างคำอธิบายภาษาธรรมชาติจาก Activations ของโมเดลภาษา ซึ่งทั้ง Anthropic และนักวิจัยกลุ่มอื่นๆ กำลังศึกษาในแนวทางใกล้เคียงกัน
Anthropic เปิดให้นักวิจัยและผู้สนใจเข้าถึง NLAs ได้แล้วในหลายช่องทาง ทั้งโค้ดสำหรับการฝึกและ NLAs ที่ฝึกเสร็จแล้วของโมเดลโอเพ่นซอร์สหลายตัวบน GitHub และ Demo แบบโต้ตอบที่ทำร่วมกับ Neuronpedia สำหรับลองเล่นว่าโมเดลคิดอะไรอยู่จริงๆ
ที่มา: Anthropic
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด


จีนทำสหรัฐฯ แบ่งเป็น ศึกสามก๊ก AI อเมริกา หลังปล่อย Kimi K3 ก๊อปเกรด A จนทำเนียบขาวตื่นตระหนก
สรุปดราม่า AI เมื่อจีนใช้เทคนิค Distillation ดึงความฉลาดจากโมเดลอเมริกัน จนกลายเป็นชนวนเหตุจุดศึกสามก๊กในสหรัฐฯ ระหว่างทำเนียบขาว ค่ายชิป และแล็บ AI...
 0
0

1,319 คนในบริษัท AI ระดับโลก ร่วมลงนาม Pacing the Frontier เรียกร้องชะลอการพัฒนา AI
พนักงานจากบริษัท AI แนวหน้าของโลกกว่า 1,293 คน ทั้งจาก OpenAI, Google, Meta, Anthropic, Microsoft, Amazon และอีกหลายบริษัท ร่วมลงชื่อในแถลงการณ์ ‘Pacing the Frontier’...
0

Thinking Machines Lab ของ Mira Murati เปิดตัว Inkling-Small โมเดล Open-weight ขนาด 276 พันล้านพารามิเตอร์ ที่เล็กลง 4 เท่าแต่ทำเหตุผลและเขียนโค้ดแซงรุ่นพี่ Inkling พร้อมความสามารถ ...
0
