
วิเคราะห์การแข่งขันด้าน AI ของสหรัฐและจีน ด้วยมิติของ Data
เรื่องราวของการแข่งขันด้านเทคโนโลยี AI ในจีนและสหรัฐฯ เป็นประเด็นที่น่าจับตา เรามีโอกาสได้เห็นบทวิเคราะห์จำนวนมาก และครั้งนี้เป็นบทวิเคราะห์จาก Matt Sheehan แห่ง Macropolo ซึ่งเป็น In-house think tank ของ Paulson Institute in Chicago
ประเด็นที่น่าสนใจและถูกหยิบยกขึ้นมานั่นคือ แม้จีนนั้นมีจุดได้เปรียบหลายจุด อย่างกรณีของเดต้า (data) ที่เก็บมาได้นั้นมีปริมาณมหาศาล จากจำนวนประชากร จำนวนสมาร์ทโฟน และการเก็บข้อมูลโดยภาครัฐตลอดเวลา จนทำให้ AI สามารถเรียนรู้จากเดต้าดังกล่าวและพัฒนาก้าวล้ำไปอีกหลายขั้นได้ แต่ทีม Macropolo วิเคราะห์ว่า แท้ที่จริงแล้วการมองเรื่องนี้ ควรมองหลากหลายแง่มุมกว่านั้น โดย หยิบยก Framework เรื่องเดต้าออกเป็น 5 มิติด้วยกัน โดยแต่ละมิติจีนอาจเหนือกว่าและบางมิติสหรัฐฯ ก็เหนือกว่า โดยแบ่งมิติออกเป็น ปริมาณ, ความลึก, คุณภาพ, ความหลากหลาย, และการเข้าถึงได้
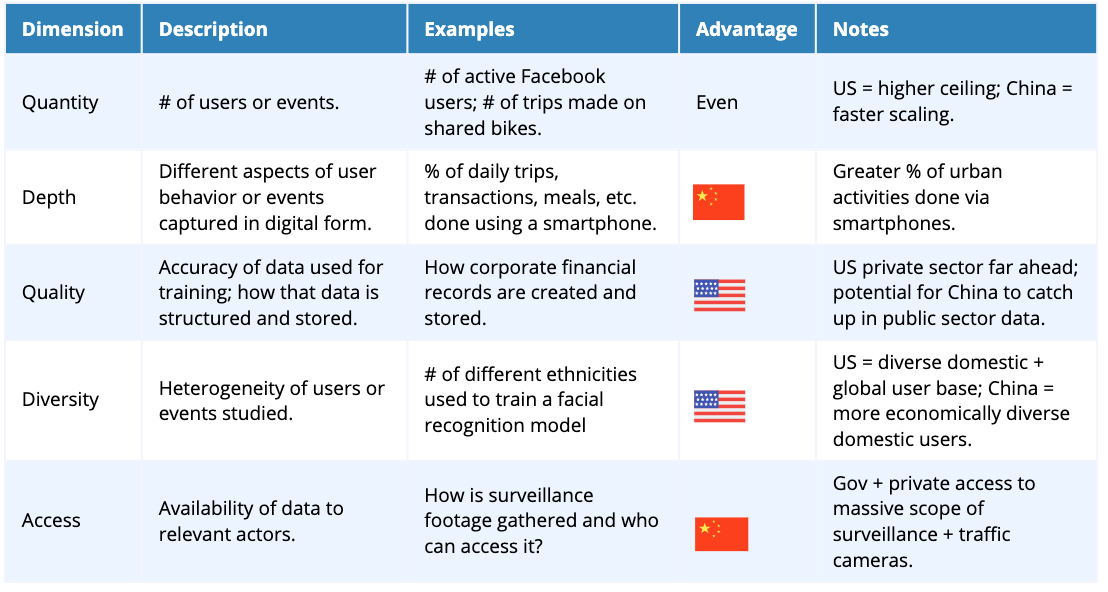 ปริมาณ (Quantity)
ปริมาณ (Quantity)
จริงอยู่ที่จีนมีปริมาณของเดต้าที่มาจากประชาชนจำนวนมาก ทำให้เป็นแต้มต่อส่วนหนึ่ง แต่ก็อย่าลืมว่าเป็นข้อมูลในประเทศจีนเป็นหลัก มีบริษัทของจีนจำนวนไม่มากนักที่สามารถขยายออกมาเพื่อครองตลาดในประเทศต่างๆ ได้ (อย่างปัจจุบันหนึ่งในนั้นคือ TikTok ที่พยายามขยับขยายไปหลายประเทศ) ในขณะที่บริษัทด้านเทคโนโลยียักษ์ใหญ่ของสหรัฐฯ ครอบครองตลาดบางส่วนของประเทศตนเองและมีฐานลูกค้า (เดต้า) ขนาดใหญ่กระจายอยู่ทั่วโลก หนึ่งในตัวอย่างที่เห็นได้ชัดคือ WeChat ที่เติบโตอย่างรวดเร็วในจีน แต่ยังไม่สามารถครองตลาดโลกได้ด้วยจำนวนผู้ใช้ 1.1 พันล้าน ในขณะที่ Facebook มีผู้ใช้อยู่ทั่วโลก 2.3 พันล้าน
เชิงลึก (Depth)
ส่วนนี้ว่าด้วยเรื่องการมองมุมที่หลากหลายของดาต้าอันเกิดจากพฤติกรรมผู้บริโภคในรูปแบบของดิจิทัล ยิ่ง AI ได้รับการสอนและเรียนรู้รูปแบบของพฤติกรรมผู้บริโภคที่แตกต่างกัน จะยิ่งทำให้สามารถคาดการณ์และแนะนำให้กับผู้ใช้ได้อย่างตรงจุดมากขึ้น ตรงจุดนี้ยอมรับว่าจีนมีความเหนือกว่าไม่น้อยเพราะบริษัทด้านเทคโนโลยีเข้าไปเกี่ยวข้องในชีวิตประจำวันของผู้ใช้มากกว่าทั้งโลกออนไลน์และออฟไลน์ผ่านทางสมาร์ทโฟนแม้พวกเขาจะอยู่ในชนบทก็ตาม ตั้งแต่การจองจักรยาน การซื้อของ สั่งอาหาร ในชีวิตประจำวัน ในขณะที่บริษัทในสหรัฐฯ จะรู้พฤติกรรมออนไลน์ อาทิ ประวัติการค้นหา การซื้อของออนไลน์ แต่ยังขาดซึ่งกิจกรรมที่เกี่ยวข้องกับโลกออฟไลน์เมื่อเทียบกับจีนอย่าง Tencent, Alibaba เป็นต้น อย่างไรก็ตามยังคงมีความพยายามของบริษัทเทคโนโลยีในสหรัฐฯ หลายรายที่พยายามเก็บเดต้าออฟไลน์โดยผ่าน Smart Home Solution อาทิเช่น Amazon’s Alexa

คุณภาพ (Quality)
ว่าด้วยเรื่องของความถูกต้องของเดต้า โครงสร้าง และการจัดเก็บของเดต้าทั้งเข้าถึงได้ง่ายและอยู่ในรูปแบบดิจิทัลเพื่อใช้สอน AI อาทิเช่น ข้อมูลด้านการเงินของสถาบันการเงิน ด้านสุขภาพเพื่อใช้วิเคราะห์คาดการณ์การเจ็บไข้ได้ป่วย ซึ่งตรงนี้สหรัฐฯ มีโครงสร้างการเก็บข้อมูลอย่างดีผ่านทาง Enterprise Software มานานกว่าจีน ซึ่ง Kaifu Lee เองก็เคยกล่าวไว้เช่นกัน ในหนังสือ AI-Super-Powers อย่างไรก็ตามในปัจจุบันจีนก็เร่งลงทุนและทรานฟอร์มข้อมูลต่างๆ ให้อยู่ในรูปแบบดิจิทัลให้เร็วที่สุดเช่นกัน
ความหลากหลาย (Diversity)
จุดนี้ทางสหรัฐฯ มีภาษีดีกว่าในแง่ของความหลากหลายทั้งคนที่อยู่อาศัยที่นั่น รวมถึงผู้ใช้บริการต่างๆ ของบริษัทเทคโนโลยีจากทั่วโลก อาทิ Google Facebook ที่มีความหลากหลายมากกว่า Wechat และ Baidu แต่ในอีกมุมหนึ่งระบบการวิเคราะห์ใบหน้าของทางจีนที่ตรวจสอบคนกว่าพันล้านใบหน้า จะเชี่ยวชาญมากในการแยกคนจีน แต่อาจจะมีปัญหาเมื่อนำไปใช้แยกแยกคนที่อยู่ในโลกตะวันตก หรือผิวดำ และแน่นอนยังมีผลกับเรื่องการวิเคราะห์เสียง เพราะมีสำเนียงที่แตกต่างกัน อย่างไรก็ตามจีนก็ยังถือเป็นคนกลุ่มใหญ่และทรงอิทธิพลต่อโลกใบนี้มาก เรียกว่าจีนได้เปรียบในเชิงการมีเดต้าเชิงลึกของชนชาตินี้ แต่สหรัฐฯ มีเดต้าที่มีความหลากหลายกว่า
การเข้าถึง (Access)
จีนได้เปรียบเป็นอย่างมากในแง่การเข้าถึงเดต้าสาธารณะ ซึ่งเป็นการรวบรวมจากโครงสร้างเน็ตเวิร์คด้านการรักษาความปลอดภัย กล้องวงจรปิด ที่สามารถวิเคราะห์การเคลื่อนไหวของ รถ จักรยาน บัส คนเดินถนน มีการจับมือร่วมกันระหว่างรัฐบาลและภาคเอกชน อาทิเช่น Alibaba เพื่อร่วมกันนำเดต้าต่างๆ มาเป็นรากฐานในการพัฒนา Smart City ในขณะที่สหรัฐฯ คงมีความกังวลเรื่องความเป็นส่วนตัวระดับบุคคลอยู่
 Framework นี้เป็นเพียงแค่หนึ่งในตัวอย่างที่นำมาใช้มองประเด็นการพัฒนาด้าน AI ของ 2 มหาอำนาจโดยมีเดต้าเป็นพื้นฐาน หนทางยังคงอีกยาวไกล เกมนี้คงต้องดูกันอีกยาวๆ
Framework นี้เป็นเพียงแค่หนึ่งในตัวอย่างที่นำมาใช้มองประเด็นการพัฒนาด้าน AI ของ 2 มหาอำนาจโดยมีเดต้าเป็นพื้นฐาน หนทางยังคงอีกยาวไกล เกมนี้คงต้องดูกันอีกยาวๆ
ที่มา: Macropolo
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด


เจาะลึกเหตุผลที่คนไทยต้องรีบหลบรถบรรทุกใหญ่ พร้อมเปิดทางแก้ปัญหาพฤติกรรมเสี่ยงจากต้นตอด้วยเทคโนโลยี AI Video Telematics ยกระดับความปลอดภัยฟลีตรถขนส่งได้ทันที...
 0
0

วิเคราะห์ 8 ปี ThailandPostMart จากจุดเริ่มต้นดันสินค้าชุมชน OTOP สู่ความท้าทายในตลาด e-Commerce ล้านล้าน มี Asset 50,000 จุด แต่ทำไมยังโตช้ากว่าที่คิด?...
0

ร้านค้าออนไลน์ไทยที่ขายผ่านแพลตฟอร์มต่างชาติ 3 เจ้าใหญ่ ต้องจ่ายค่าธรรมเนียมรวมกันสูงถึง 22-40% ของยอดขายทุกคำสั่งซื้อ ตัวเลขนี้มาจากการสำรวจ SME กว่า 500 รายในช่วงไตรมาส 1-2 ปี 25...
0
