
แกะระบบ Infrastructure ของ Wongnai และ Jitta [สรุปเนื้อหาจากงาน Code Mania 11 : Raise the Bar]
มาลองดูกันว่า Startup ชื่อดังของไทย อย่าง Wongnai และ Jitta เขามีวิวัฒนาการของ Infrastructure (สถาปัตยกรรมของผลิตภัณฑ์) อย่างไรบ้าง เปิดเผยประสบการณ์โดย CTO ของทั้งสองที่ พร้อมคำแนะนำสำหรับ Startup
ผู้เขียนได้มีโอกาสเข้าร่วมงาน Code Mania 11 : Raise the Bar จัดโดยสมาคมโปรแกรมเมอร์ไทย เนื้อหาในงานเหมาะสำหรับโปรแกรมเมอร์ที่ต้องการแลกเปลี่ยนและยกระดับความรู้ความสามารถ ผู้เขียนในฐานะที่เคยมีพื้นฐานมาบ้าง จะขอนำสิ่งที่ได้เรียนรู้มาสรุปเล่าต่อ โดยพยายามจะเขียนให้ทั้งโปรแกรมเมอร์อ่านดี และคนที่ไม่ใช่โปรแกรมเมอร์แต่มีพื้นฐานคอมพิวเตอร์บ้าง สามารถอ่านเพื่อเห็นมุมมองทางเทคโนโลยีได้ค่ะ

แกะสถาปัตยกรรม Wongnai
คุณบอย CTO ของวงใน เริ่มจากการฉายภาพกว้างให้เห็นองค์ประกอบสำคัญของระบบวงใน ดังภาพต่อไปนี้

โดยปัจจุบันมีสถิติการใช้งาน ดังนี้
- 3 แสน session การใช้งาน ต่อวัน, 53 ล้านเพจวิว ต่อเดือน
- คิดเป็น desktop 20% mobile 80% ซึ่งในส่วนของ mobile มาจาก app 66% และ web 34%
- Peak time ของวงในจะสอดคล้องตามมื้ออาหารของคนทั่วไป ช่วงมื้อเที่ยง ช่วงมื้อเย็น กับช่วงวันหยุด Weekend และวันพิเศษ เช่น วาเลนไทน์ ตรุษจีน วันหยุดยาว จะมีผู้ใช้งานสูงเป็นพิเศษ นอกจากนี้ยังมีช่วงเวลาหลังจาก push notification หรือมีการลงบทความหรือเกิดดราม่าขึ้น ก็จะเกิด spike ขึ้นมาเช่นกัน
การจัดการ Email
- MailChimp คือบริการ Email marketing ที่วงในเลือกใช้ในช่วงเริ่มต้น จนมาถึงปี 2012 ที่ยอดผู้ใช้สูงถึง สองแสนคน ก็ได้ตัดสินใจจะตั้ง Mail server ของตัวเอง เนื่องจาก MailChimp เป็นบริการที่มีราคาเหมาะกับระยะตั้งต้น ตรงกันข้ามหากมีผู้ใช้มาก จะคิดค่าบริการแพง
- ตัดสินใจตั้ง Mail server ของตัวเองโดยเลือกใช้ openEMM แต่ปัญหาที่เกิดขึ้นคือ เมลออกช้ามาก, กิน Bandwidth สูง แถมเมลที่ส่งไปมักตกอยู่ใน junk อีกด้วย
- เลยตัดสินใจหันมาใช้ Amazon SES บริการ Mail server ของอเมซอน ส่งเมลได้ 90 ฉบับต่อวินาที แถมเป็น Whitelist domain ทำให้เมลที่ออกจากโดเมนนี้ไม่ตก junk และไม่โดนมองว่าเป็น spam โดยปัญหาระหว่างการ switch ไปใช้คือ ยังไม่ได้เรทความเร็วที่ 90 ฉบับต่อวิ ในช่วงแรกๆ แต่จะค่อยๆเพิ่มให้ทีหลัง
SEO & Scaling
- 2012 วงในมี pages ในเว็บประมาณแสนกว่าเพจ แต่เมื่อเช็คด้วย Google Webmaster Tool พบว่า Google bot มา crawl (เก็บข้อมูลไปใส่ Google) ไปแค่หมื่นกว่าเพจเท่านั้น โดยสาเหตุมาจาก latency หรือความช้าในการโหลดเพจนั่นเอง เพจที่โหลดช้า bot จะขี้เกียจเข้ามา crawl ค่ะ และถ้ามันไม่ crawl ก็จะเซิร์จไม่เจอ ส่งผลเสียต่อ SEO
- นอกจากจะต้องพัฒนาเรื่องความเร็วของ network แล้ว วงในเองก็ตั้งเป้าว่าปลายปี 2013 จะรองรับผู้ใช้งาน 1 ล้านคน ดังนั้นจึงต้องมีการเปลี่ยน server เพื่อให้ scale ได้ จึงตัดสินใจเลือกใช้ Cloud โดยเลือกใช้ของ Amazon
- Challenge ที่มีก็คือการย้ายข้อมูลมหาศาลไป Cloud (ตัวอักษรยังไม่เท่าไร แต่ที่ท้าทายคือไฟล์ภาพ ซึ่งวงในมีข้อมูลไฟล์ภาพรีวิวเยอะมาก เป็นล้านๆรูป) ทำยังไงให้มี downtime (ระบบล่ม) ให้เกือบเท่ากับศูนย์ให้ได้ และ mobile app ต้องไม่เกิดความเสียหาย
- ทีม Dev ของวงในรับมือโดยการเขียน script ให้ทำ automate upload ไฟล์ภาพจากเซอร์เวอร์ตัวเองขึ้นไปบน Cloud เรื่อย ๆ แล้วมี flag status ตัวนึง เอาไว้ระบุว่า ไฟล์นี้ถูกอัพโหลดไปหรือยังเวลาเรียกรูปภาพก็ให้เช็คที่ flag ตัวนี้ ถ้าอัปแล้วก็ไปเรียกบน Cloud ถ้ายังไม่อัปก็เรียกบน server ตัวเอง
Database (ฐานข้อมูล)
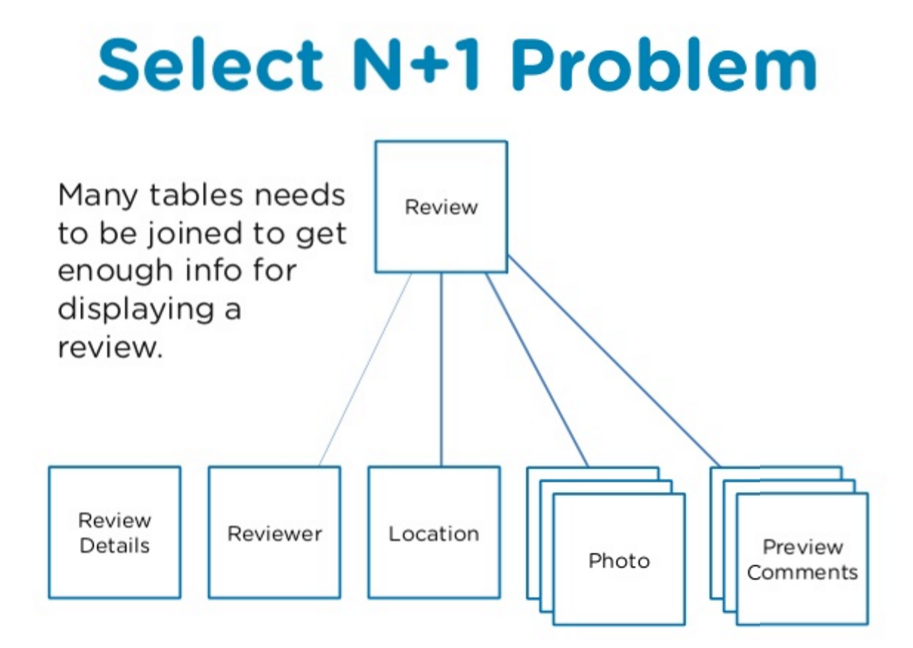
- กว่าจะครบองค์ประกอบหนึ่งรีวิวนั้น ประกอบไปด้วยการรวมร่างกันของข้อมูลหลายๆชนิด ทั้งข้อความที่รีวิว ข้อมูลของผู้รีวิว ข้อมูลสถานที่ รูปภาพ และคอมเม้น ข้อมูลแต่ละประเภทถูกเก็บไว้ในตาราง (table) ของประเภทนั้นๆ เราต้องทำการ join (รวมข้อมูลเข้าด้วยกัน) สารพัด tables แต่ปัญหาคือ แต่ละ table เองก็ข้อมูลเยอะขึ้นทุกวันๆ กว่าจะ join เสร็จจึงใช้เวลานาน
- วิธีปกติคือการเขียนคำสั่ง query (ดึงข้อมูล), join table ที่ฝั่งฐานข้อมูล แล้วค่อยส่งผลลัพธ์มาที่ server ทีเดียว แต่ด้วยความที่วงในมีข้อมูลมาก กว่าจะ join ก็เสร็จช้า
- ก็เลยเปลี่ยนวิธีมาเป็น query แต่ละ table แล้วส่งผลลัพธ์คร่าวๆมาก่อน แล้วมารวมผลลัพธ์เอาเอง เพื่อลดการทำงานใน database ลง ผลก็คือประสิทธิภาพดีขึ้นอย่างเห็นได้ชัด
- ทีนี้อยู่มาวันนึงทีมงานตัดสินใจที่จะ merge รวม 2 products ของวงในเข้าด้วยกัน คือ Wongnai Food กับ Wongnai Beauty ซึ่งเมื่อก่อนทำแยกส่วนกัน ทำให้ต้องมีการเพิ่ม column ของ table ขึ้นมาเพื่อรองรับกันและกัน ซึ่งมันเหมือนจะง่ายก็แค่เพิ่ม ก๊อป วาง แต่เพราะจำนวน records มันสูงมาก กว่าจะทำหมด แถมยังติดปัญหา IOPS ( Input/Output Operations Per Second ) ของ Amazon ที่ทำการลิมิตอัตราการ read/write storage ของเครื่องบน Cloud อีกด้วย วิธีแก้ก็คือ สร้างเครื่องใหม่บน Amazon ให้เรียบร้อย โดยเลือกขนาด storage ที่ขนาดใหญ่ขึ้นอีก (เพื่อให้ได้ burst duration ที่นานขึ้น) หลังจาก instance ถูกสร้างเรียบร้อย จะรอให้ credit ของการ Burst กลับมาใหม่พร้อมใช้ได้แบบเต็มที่ แล้ว่จึงค่อยเริ่มทำการเปลี่ยนแปลง schema ของ database อีกที
Search & Indexing
- รูปแบบการ search ของวงในมีหลายแบบ เช่น ร้านอาหารรอบตัวขณะนี้, ร้านอาหารในสถานที่ที่ระบุไว้, สาขาของร้านนั้น ๆ, Text เปล่าๆ ไม่ได้ระบุอะไรเลย ก็มี
- วงในใช้ Apache Solr ในการทำระบบ indexing ซึ่งมีข้อจำกัดคือ อ่านเร็วแต่เขียนช้า (query เร็ว update ช้า) ซึ่งผิดกับความต้องการของวงในที่ต้องการความเร็วทั้งคู่ เพราะทุก ๆ การ check-in, like, review ร้านอาหาร มีผลต่อระบบ ranking ทั้งหมด แต่พอใช้อัปเดตแบบ real-time ผลลัพธ์ที่ออกมาก็ยังไม่ค่อยน่าพอใจเท่าไหร่ เพราะยังช้าไป ตรงนี้คุณบอยบอกเพียงว่าใช้วิธีเพิ่ม batch processing เข้าไปอีกชั้นนึง
- สาเหตุที่ไม่ใช้ Amazon Elastic Search ก็เพราะว่า การ test มันยาก ต้องต่อเน็ตตลอดเวลา แถมรัน test บนเครื่อง local ไม่ได้ รวมถึงไม่อยากพึ่งพา Amazon ไปตลอด วันนึงในอนาคตอาจจะมี Cloud เจ้าอื่นที่ดีกว่า Amazon วงในก็พร้อมที่จะมูฟไปหาสิ่งที่ดีกว่าเดิมได้ทันที
Caching
- Cache คือหน่วยความจำพิเศษไว้เก็บข้อมูลใช้บ่อย จะได้โหลดเร็วกว่าไปเอาที่หน่วยความจำอื่น เคสของวงใน มีผู้ใช้เรียกข้อมูลที่หลากหลายมาก ต่างคนก็ต่างร้าน ต่าง location ทำให้ไม่เหมาะจะ cache รีวิวใดเป็นพิเศษ
- สิ่งที่วงในสามารถ cache ไว้ได้มีไม่เยอะ ตัวอย่างที่ cache ได้เช่น บทความของวงในเอง กับไกด์ต่าง ๆ ที่ไม่มีความเปลี่ยนแปลง และผู้อ่านทุกคนเปิดมาเห็นข้อมูลเดียวกันหมด ระบบที่ใช้คือ EHCache
Scheduled Tasks
- คือการตั้งเวลาให้ระบบทำงานที่เป็น routine โดยอัตโนมัติ
- ใช้ Quartz ในการ automate tasks ต่าง ๆ เช่น การอัปเดต rank ของร้านอาหาร, การทำ leaderboard, อัปเดต stat ของ asset ต่าง ๆ เช่น จำนวนรูป จำนวนรีวิว
Web Stack

6 ปีก่อน ทีม dev ของวงในค่อนข้างใหม่กับ web technology สมัยนั้นยังไม่มี preprocessor ที่ช่วย compile ไฟล์ javascript/css หลายๆ ไฟล์เข้าไว้ด้วยกัน ก็เลยต้องเขียนขึ้นมาเองแล้วนำไปรันในเฟส Prepare Package ของ Maven ปัจจุบันยังใช้ YUI เพื่อบีบอัดไฟล์ JavaScript และ CSS
Process และ Tools ในการทำงาน
- ใช้ Asana กับ Slack เป็นตัว Management งานต่าง ๆ ร่วมกับ Google Docs
- ใช้ Agile methodology มี Daily Scrum ส่วน Sprint cycle อยู่ที่ 2 สัปดาห์ (จากเมื่อก่อน 1 เดือน) และมีการ retrospect ทุก ๆ cycle
- ปัจจุบันทีม dev มี full-stack web 6 คน, iOS developers 3 คน + 1 part-timer, Android developers 2 คน, QA engineer 1 คน, และ UX/UI engineer 1 คน (และคุณบอยบอกด้วยว่ายังรับเพิ่มอยู่นะจ้ะ)
Q & A
- ได้มีการทำระบบ Auto scaling ไหม?
ตอบ: ตอนนี้ยังไม่มี ก่อนหน้านี้ไม่ได้ทำ เพราะสมัยนั้นยังทำยากอยู่ ปัจจุบันทำง่ายขึ้น แต่ยังเป็นงานที่ไม่ได้มีความจำเป็น นอกจากนี้เครื่องบน Amazon ที่ได้ซื้อไว้เราก็จ่ายเป็นแบบเหมาเพื่อเปิดใช้งานตลอด ด้วยเหตุผลที่ว่าราคาถูกกว่าแบบที่ต้องการเปิดๆ ปิดๆ ทำให้เราไม่ได้ประโยชน์อะไรมากถ้าทำเรื่อง autoscaling แต่ในอนาคตถ้ามีเวลาก็อาจจะทำ
- ทำไมถึงไม่ใช้ Angular หรือ React (Front-end frameworks ที่ได้รับความนิยมในตอนนี้)?
ตอบ: ถ้าเปลี่ยน architecture แล้วผลลัพธ์ไม่ต่างจากเดิม คือไม่ได้ส่งผลลัพธ์โดยตรงในด้าน business ก็ยังไม่คุ้มค่าที่จะเปลี่ยน ในขณะที่การเปลี่ยนเทคโนโลยี หมายถึงการเปลี่ยน Skill ของคนในทีมด้วย คนในทีมก็ต้องพร้อมด้วย
- ทำไม Database ถึงยังใช้ SQL ไม่ใช้ NoSQL?
ตอบ: เราเน้น ACID Transaction และสมัยนั้น NoSQL ยังใหม่มากๆ จึงห่วงเรื่องความเสถียร ในอนาคตมีแผนที่จะใช้งานแบบผสม SQL กับ NoSQL

Next-steps
- วงในร่วมมือกับภาควิชาวิศวกรรมคอมพิวเตอร์ จุฬาฯ พัฒนาระบบวิเคราะห์ข้อมูลผู้ใช้งานมากขึ้น โดยใช้ machine learning และเลือกใช้ภาษา Scala และใช้ Spark เป็นเครื่องมือประมวลผลข้อมูล Big Data ที่วงในมี เพื่อให้เข้าใจพฤติกรรมผู้ใช้มากขึ้น
- เริ่มใช้ NoSQL สำหรับข้อมูลที่ไม่ต้องการการ search เช่น notifications และ feed ต่าง ๆ
- Advanced Message Queuing Protocol (AMQP) ด้วย RabbitMQ สำหรับให้ service ต่างๆ คุยกันได้เพื่อรองรับ architecture ในอนาคต
- เปลี่ยน Architecture เป็น Microservices
- เริ่มทำ Image server
สำหรับสไลด์การบรรยาย สามารถดูได้ที่นี่ค่ะ
ขอบคุณคุณบอย ภัทราวุธ ซื่อสัตยาศิลป์ จาก Wongnai.com สำหรับเนื้อหาดีๆ และความช่วยเหลือในการตรวจสอบและแก้ไขบทความ และขอขอบคุณ แชมป์ อัครพล ผดุงดิษฐ์ เพื่อนของผู้เขียน ที่มีส่วนช่วยในการเขียนเนื้อหาส่วนนี้ด้วยค่ะ
คำแนะนำเรื่อง Cloud Infrastructure จาก Jitta
ช่วงบ่ายคุณฮันท์ CTO ของ Jitta ได้มาแชร์ประสบการณ์ และแนวคิดที่ใช้ในการทำงานหลายอย่าง โดยเริ่มจากกล่าวว่า "Few engineers can do more" แล้วยกตัวอย่างเคสของ Instagram บริษัทมูลค่าพันล้านเหรียญ ที่เคยมีพนักงานอยู่เพียง 13 คน เป็นวิศวกรหรือโปรแกรมเมอร์เพียง 6 คนเท่านั้น ที่ Instagram ทำได้ เป็นเพราะว่าตัว product เองก็ไม่ได้มีฟีเจอร์มากมายหวือหวามาตั้งแต่ต้น แต่เกิดจากการค่อยๆ เพิ่มฟีเจอร์ ตามช่วงเวลาที่เหมาะสม เช่น ตามการเติบโตของ users ในระบบ
Great Infrastructure for Startups
ที่ Jitta เชื่อว่า Great Infrastructure = Development Speed + More Creative + More Growth หมายถึงสิ่งสำคัญสำหรับสถาปัตยกรรมที่ดี คือการเอื้อให้ผู้พัฒนาพัฒนาได้เร็ว, ได้อย่างสร้างสรรค์ และเอื้อต่อการเติบโต วันนี้คุณฮันท์จึงมาแนะนำในเรื่องการใช้ Cloud มีประโยชน์มากกับคุณสมบัติของ Infrastructure ที่ดี แต่ปัญหาที่มักพบก็คือ
- บริษัทส่วนใหญ่ใช้ Cloud เพียงเพื่อเป็น Data center สำหรับเก็บข้อมูลเท่านั้น
- บริษัทส่วนใหญ่พยายามสร้างและดูแลโปรแกรมต่างๆ ด้วยตัวเองลำพัง
ในการทำงานจริง มีอะไรที่ฝั่ง technology ต้องดูแลจัดการหลายเรื่อง ไม่ว่าจะเป็น
- Development > เรื่องของ Framework, Repo และ Workflow
- Deploy > การ Test การ Build
- Infra > Logging และการดู Metrics ทั้งทาง Business และทาง Resources
หรือถ้าให้ดูภาพทั้งหมด มันจะมีเรื่องต่อไปนี้
หลายๆเรื่องเป็นเรื่องที่เราสามารถใช้เครื่องมือของ Cloud platform ช่วยได้ หรือใช้เครื่องมืออื่นๆ มาช่วยทำงานประกอบ คุณฮันท์ได้แนะนำ Startup ให้ลองใช้ Heroku เป็น Cloud platform ที่มาพร้อมสารพัดประโยชน์ที่ช่วยอำนวยความสะดวกต่างๆ ได้มากมาย เช่น สั่ง push แล้วมัน build ให้เสร็จสรรพ สามารถ monitor ได้เลย รู้ log เลย อยาก scale ก็ทำได้ง่ายๆ แค่พิมพ์คำสั่งเดียว
แต่สำหรับ Jitta ปัจจุบันใช้ Google Cloud Platform เนื่องจากเผอิญว่าก่อนหน้านี้ Heroku มีปัญหาที่ไม่ตอบโจทย์อยู่ (แต่ตอนนี้ระบบมันดีกว่าก่อนมากแล้ว)
เครื่องมืออื่นๆ ที่คุณฮันท์ฝากไว้
- Git repo เช่น Github, Gitlab ( Jitta ใช้ทั้งคู่ )
- Continuous integration เช่น Codeship, CircleCi, Travis หรือจะติดตั้งใช้ภายในด้วยตัวเองกับJenkins ( ส่วน Jitta เลือกใช้ CircleCi )
- CoreOS ระบบปฏิบัติการสำหรับ Cluster รองรับการเพิ่มของเครื่อง และ มีระบบแจกจ่ายการทำงานภายในตัว
- Spinal เป็น Framework สำหรับช่วยจัดการ Microservices ( Jitta สร้างเครื่องมือขึ้นมาเองเป็น Node.JS microservices framework )
- Kubernetes ระบบที่จะช่วยบริหาร Cluster สามารถติดตั้งบน Cloud ของตัวเองได้ หรือถ้าใช้ Google Cloud อยู่แล้วก็มี Google Container Engine
บทเรียนที่ฝากไว้
- สิ่งที่ Jitta ให้ความสำคัญคือ keep engineers happy
- more time and more productivity
- ไม่กลัวที่จะครีเอทและเปลี่ยนแปลงโค้ด
- ถึงแม้จะใช้ Cloud แต่ปัญหาก็สามารถเกิดขึ้นได้หมด ไม่ว่าจะเป็น Disk crashed, Database crashed, Machine crashed อะไรก็เกิดขึ้นได้ ดังนั้นเราต้องมีแผนรับมือด้วย
- อย่ายึดติดกับความเสถียรที่ Cloud มีให้ พึงระลึกไว้เสมอว่า Instance ที่สร้างไว้พร้อมจะมีปัญหาได้เสมอ แล้วถ้ามีจะทำอย่างไร?
- ที่ Jitta มีการสั่งให้ machine randomly shutdowns ตัวมันเอง เป็นการลองเทสดูว่าถ้าเครื่องเกิดดับแบบไม่คาดคิด ระบบจะสามารถรับมือได้หรือไม่
- สำหรับ Startup อย่าคิดแต่เรื่องประหยัดจนเกินไป ต้องยอมจ่ายให้เครื่องมือบ้าง ให้คิดว่าไม่งั้นเราอาจจะเสียอะไรที่มากกว่าเงิน คือทั้งเรื่องค่าแรง และค่าเวลา (ซึ่งเวลาสำคัญมากสำหรับ Startup)
- เรื่อง infrastructure ไม่ใช่เรื่องที่เราสามารถเขียนออกมาเป็น how-to ได้
- เพราะ infrastructure ขึ้นอยู่กับ product อย่าง Jitta เป็น financial ถ้าให้เลือกระหว่างความเร็วกับความถูกต้องของข้อมูล ความถูกต้องของข้อมูลจะสำคัญกว่า ในขณะที่ Wongnai เป็นแนว content ก็จะเป็นอีกแบบหนึ่ง
- เลือกเทคโนโลยีที่เหมาะสมกับช่วงเวลา เหมาะสมกับ Startup นั้นๆ ของคุณ และเรียนรู้จากข้อผิดพลาดให้มากๆ
- ถ้าสนใจรายละเอียดเกี่ยวกับวิธีการพัฒนาเพิ่มเติม สามารถดูได้จาก Blog ของทีม Jitta
- สไลด์การบรรยาย
ขอขอบคุณคุณฮันท์ที่ได้ให้ความรู้ดีๆ และช่วยตรวจสอบแก้ไขเนื้อหาด้วยนะคะ
จะเห็นได้ว่ามีจุดร่วมหนึ่งที่เห็นได้เหมือนกันจาก CTO ทั้งสองท่านคือ พวกเขาไม่ได้เลือกเทคโนโลยีตามกระแส แต่ให้ความสำคัญกับการเลือกให้สอดคล้องกับคุณสมบัติของ product สอดคล้องกับ business requirement และให้ความสำคัญเรื่องการทำงานของคนในทีม หวังว่าผู้อ่านจะได้เห็นแนวคิดดีๆ จากบทความนี้นะคะ และอย่าลืมติดตามข่าวสารต่างๆ ของสมาคมโปรแกรมเมอร์ไทย ซึ่งมีการสนับสนุนและงานอบรมดีๆ มีอีกมากมาย
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด


เจาะลึกเหตุผลที่คนไทยต้องรีบหลบรถบรรทุกใหญ่ พร้อมเปิดทางแก้ปัญหาพฤติกรรมเสี่ยงจากต้นตอด้วยเทคโนโลยี AI Video Telematics ยกระดับความปลอดภัยฟลีตรถขนส่งได้ทันที...
 0
0

วิเคราะห์ 8 ปี ThailandPostMart จากจุดเริ่มต้นดันสินค้าชุมชน OTOP สู่ความท้าทายในตลาด e-Commerce ล้านล้าน มี Asset 50,000 จุด แต่ทำไมยังโตช้ากว่าที่คิด?...
0

ร้านค้าออนไลน์ไทยที่ขายผ่านแพลตฟอร์มต่างชาติ 3 เจ้าใหญ่ ต้องจ่ายค่าธรรมเนียมรวมกันสูงถึง 22-40% ของยอดขายทุกคำสั่งซื้อ ตัวเลขนี้มาจากการสำรวจ SME กว่า 500 รายในช่วงไตรมาส 1-2 ปี 25...
0
