
Claude เปิดตัว แผนภาพ Interactive แปลงข้อมูลเป็นภาพจำลองได้ใน Prompt เดียว ข้อมูลเปลี่ยนตามบริบทได้แบบเรียลไทม์
Anthropic อัปเดต Claude ให้กลายเป็น “ห้องเรียนมีไวท์บอร์ด” มากขึ้น ด้วยความสามารถสร้างกราฟ แผนภาพ และภาพอินเทอร์แอคทีฟ แทรกขึ้นมาในหน้าคุยแบบอัตโนมัติ โดยฟีเจอร์นี้กำลังทยอยเปิดให้ผู้ใช้ทุกคนและเปิดใช้งานเป็นค่าเริ่มต้นแล้ว
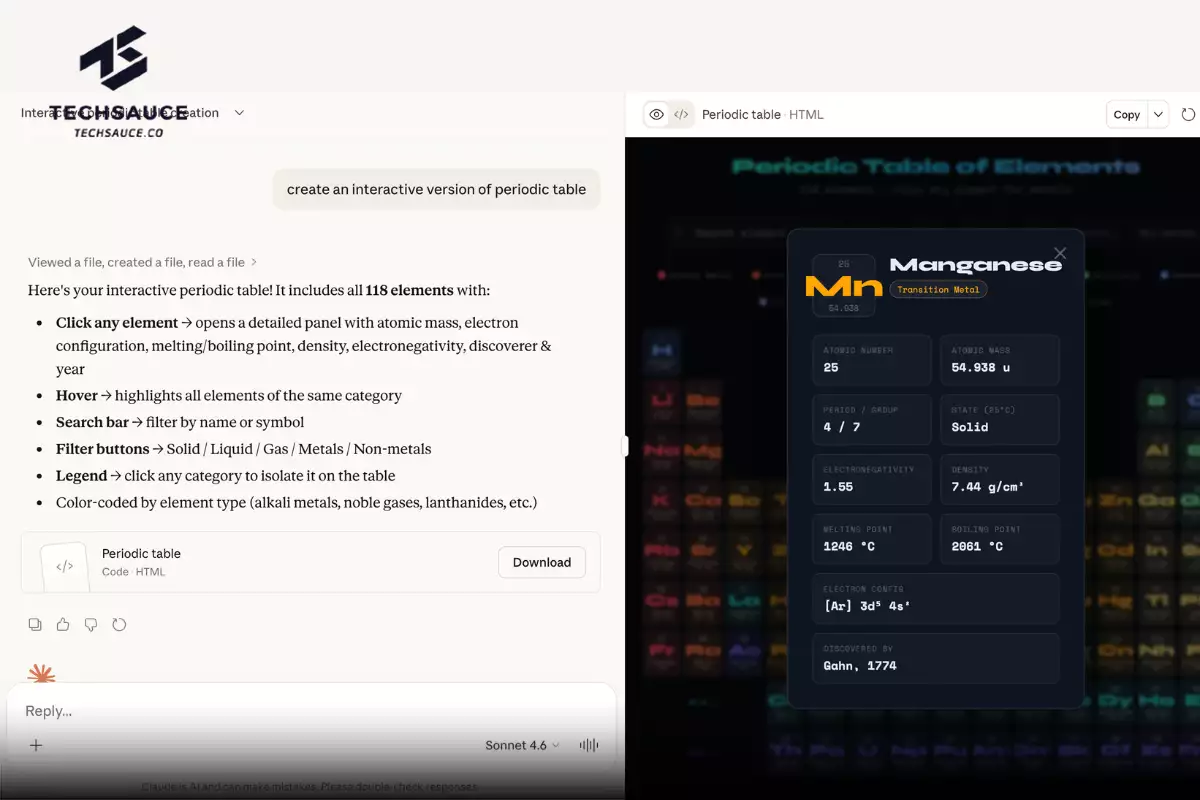
Claude วาดกราฟ–ผังงานให้ดูได้ตรงในห้องแชต
Anthropic เปิดตัวความสามารถใหม่ให้ Claude สร้างภาพอย่างกราฟ แผนผัง และ visualization รูปแบบต่างๆ แสดง “อินไลน์” อยู่ในข้อความตอบกลับ แทนที่จะไปโผล่ในแถบด้านข้างเหมือนก่อนหน้า ถ้า Claude ประเมินจากบริบทการสนทนาแล้วเห็นว่าการอธิบายด้วยภาพจะช่วยให้เข้าใจง่ายขึ้น มันจะสร้างภาพแทรกให้เองโดยที่ผู้ใช้ไม่ต้องสั่งเป็นพิเศษ
ตัวอย่างที่ Anthropic ยกคือ หากคุณกำลังคุยเรื่องตารางธาตุ Claude สามารถสร้าง Visualization ของตารางธาตุที่มีองค์ประกอบแบบอินเทอร์แอคทีฟให้คลิกแต่ละช่องเพื่อดูข้อมูลเพิ่มได้ หรือถ้าถามเรื่อง “น้ำหนักไหลผ่านโครงสร้างอาคารอย่างไร” Claude ก็สามารถสร้างภาพประกอบการกระจายน้ำหนักในอาคารให้เห็นเป็นรูปธรรม
นอกจากการทำงานแบบอัตโนมัติแล้ว ผู้ใช้ยังสามารถสั่งให้ Claude สร้าง Diagram, Table หรือ Chart ได้ตรงๆ เช่น ขอกราฟสรุปตัวเลข, ผัง Workflow, ผังสถาปัตยกรรมระบบ หรือ Decision Tree สำหรับงานซัพพอร์ตได้เหมือนกำลังให้ AI ช่วยสเก็ตช์ไอเดียบนไวท์บอร์ด
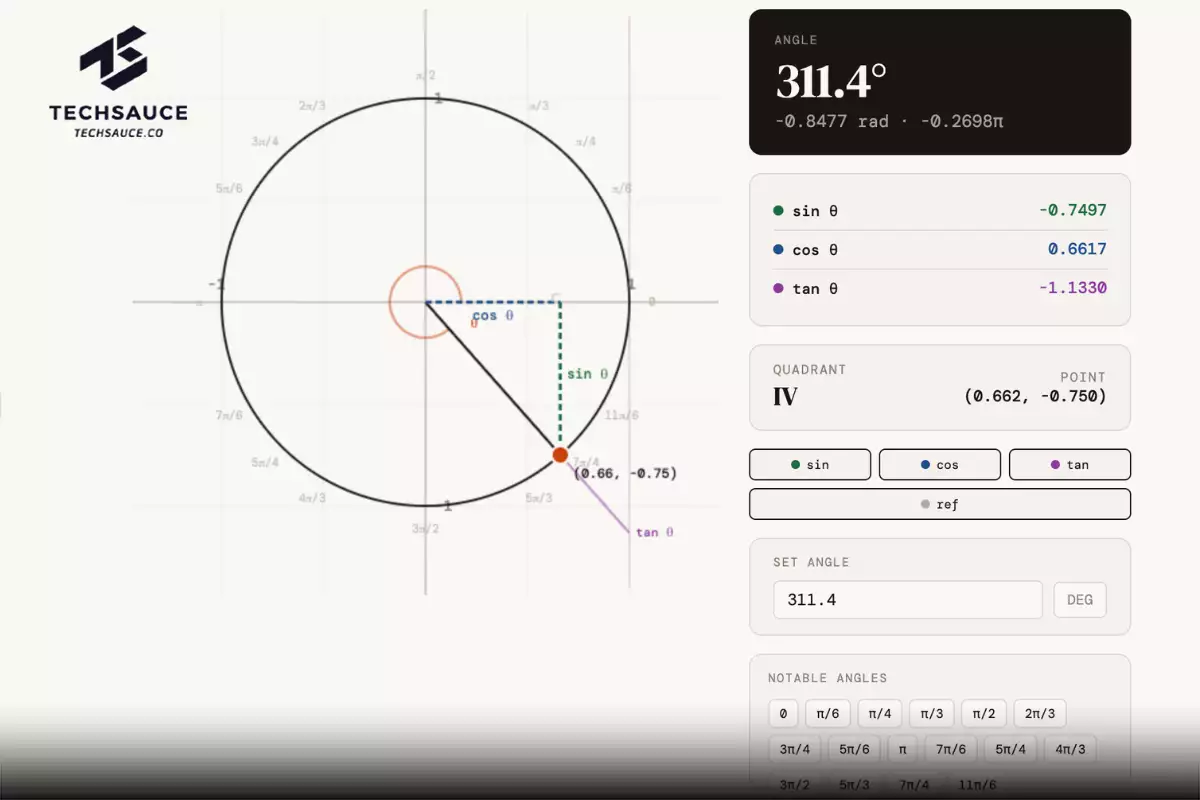
จาก Artifacts สู่ “visual workspace” ในห้องแชต
ก่อนหน้านี้ Anthropic มีฟีเจอร์ Artifacts ที่ให้ผู้ใช้สร้างชาร์ต เอกสาร โค้ด ไปจนถึงโปรโตไทป์แอปในแผงด้านข้าง โดย Artifacts จะอยู่คงที่ แก้ไข แชร์ หรือดาวน์โหลดไปใช้งานต่อได้ เหมาะกับการทำ “ชิ้นงาน” ที่อยู่นอกเหนือบทสนทนา
ฟีเจอร์ Visualizations ตัวใหม่แตกต่างออกไป เพราะภาพที่สร้างขึ้นในบทสนทนาจะ “ไหลไปกับแชต” คือเปลี่ยนแปลงหรือหายไปได้เมื่อบริบทการคุยเปลี่ยนไป ทำให้บทสนทนากับ Claude กลายเป็นเหมือน Visual Workspace ที่คุณไอเดีย–ลอง–ปรับ–ทิ้ง–ลองใหม่ ได้ในที่เดียว โดยไม่ต้องสลับไปมาในหลายเครื่องมือ ผู้ใช้ยังสามารถสั่งให้ Claude แก้ไขภาพที่สร้างขึ้น ไม่ว่าจะเป็นปรับข้อมูล รูปแบบกราฟ หรือโครงสร้างแผนภาพ แล้วให้มันเรนเดอร์เวอร์ชันใหม่ทันที
แข่งเดือด: OpenAI และ Google ก็เดินเกมด้าน Visual Learning
การอัปเดตของ Anthropic เกิดขึ้นในจังหวะที่ผู้เล่นรายใหญ่รายอื่นกำลังดัน “AI + Visual Learning” อย่างจริงจังเช่นกัน
- OpenAI เพิ่งเพิ่มความสามารถให้ ChatGPT สร้าง Visual แบบอินเทอร์แอคทีฟสำหรับคณิตศาสตร์และวิทยาศาสตร์ เช่น กราฟสมการ ภาพเรขาคณิต หรือโมเดลฟิสิกส์ ผู้ใช้สามารถปรับตัวแปรหรือสมการแล้วเห็นผลลัพธ์เปลี่ยนแบบเรียลไทม์ได้ ฟีเจอร์นี้รองรับหัวข้อคณิต–วิทย์หลักๆ กว่า 70 หัวข้อและทยอยเปิดให้ผู้ใช้ ChatGPT ที่ล็อกอินทั่วโลก
- ฝั่ง Google Gemini ก็พัฒนา “Interactive Images” สำหรับการเรียนรู้ ช่วยให้ผู้ใช้แตะส่วนต่างๆ ในภาพ เช่น ระบบย่อยอาหารหรือส่วนประกอบของเซลล์ เพื่อเปิดพาเนลอธิบายแบบละเอียดและถามต่อยอดได้ เป้าหมายคือเปลี่ยนการเรียนจากการดูภาพนิ่งเฉยๆ ไปสู่การสำรวจเชิงโต้ตอบ
แนวโน้มนี้สะท้อนว่าศึก AI รุ่นใหม่ไม่ได้แข่งกันแค่ความฉลาดในการตอบเป็นข้อความ แต่กำลังขยายไปสู่การเป็น “สื่อการสอน” ที่รวมข้อความ โค้ด และภาพอินเทอร์แอคทีฟไว้ในที่เดียว เพื่อรองรับทั้งผู้ใช้สายวิเคราะห์ข้อมูล สายดิจิทัลโปรดักต์ และผู้เรียนในระบบการศึกษา
ที่มา: The Verge
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด

EV ฝั่งจีนขึ้นแท่นรถที่คนใช้งานสั้นกว่าโทรศัพท์ คนจีนใช้รถเฉลี่ยแค่ 1.8 ปีก็เปลี่ยน
คนจีนถึงเปลี่ยนรถ EV ไวกว่าสมาร์ตโฟน ด้วยอายุเฉลี่ยบนท้องถนนเพียง 1.8 ปี เจาะลึก 3 เหตุผลหลัก ทั้งเทคโนโลยีที่ไปไว ราคาขายต่อที่ตกแรง และพฤติกรรมผู้บริโภคยุคใหม่ที่เน้นความอัจฉริยะ...
 0
0

รู้จัก HiberTec Homes บ้านไฮดรอลิกจากสหรัฐฯ ที่มุดลงห้องนิรภัยใต้ดินได้ทั้งหลังใน 15 นาที สั่งงานผ่านแอป ตัดไฟ น้ำ แก๊ส อัตโนมัติ ทนความร้อนถึง 1,090 องศาเซลเซียส ทางเลือกใหม่ของบ้...
0

บีโอไอ อนุมัติให้ เนสท์เล่ ยักษ์ใหญ่ธุรกิจอาหารและเครื่องดื่มระดับโลก ทุ่มลงทุน 23,000 ล้านบาท ก่อสร้างโรงงานผลิตกาแฟแห่งใหม่ด้วยเทคโนโลยีล้ำสมัย พร้อมศูนย์กระจายสินค้า ปั้นไทยให้เ...
0
