
Google เปิดตัว Gemini Embedding 2 ผสานข้อความ, รูปภาพ, วิดีโอ จบใน API เดียว หมดปัญหาประมวลผลข้อมูลหลายแบบ

Google เปิดตัว Gemini Embedding 2 ในฐานะโมเดล Embedding มัลติโมดัลตัวแรกที่สร้างขึ้นบนสถาปัตยกรรม Gemini โดยตรง พร้อมให้ใช้งานผ่าน Public Preview บน Gemini API และ Vertex AI ทันที ถือเป็นก้าวสำคัญที่ยกระดับความสามารถของ AI ให้พ้นจากขีดจำกัดของการประมวลผลข้อความเพียงอย่างเดียว
Embedding คืออะไร และทำไมถึงสำคัญ
โดยพื้นฐานแล้ว Embedding คือกระบวนการแปลงข้อมูล ไม่ว่าจะเป็นข้อความ รูปภาพ หรือเสียง ให้กลายเป็นชุดตัวเลข (Vector) ที่สะท้อน "ความหมาย" ของข้อมูลนั้น เพื่อให้ AI สามารถเปรียบเทียบ ค้นหา และวิเคราะห์ความสัมพันธ์ระหว่างข้อมูลได้อย่างแม่นยำ เทคโนโลยีนี้อยู่เบื้องหลังการทำงานของ Retrieval-Augmented Generation (RAG), การค้นหาเชิงความหมาย (Semantic Search) ไปจนถึงระบบวิเคราะห์ความรู้สึก (Sentiment Analysis) ที่ใช้งานกันอยู่ในผลิตภัณฑ์ Google หลายตัว
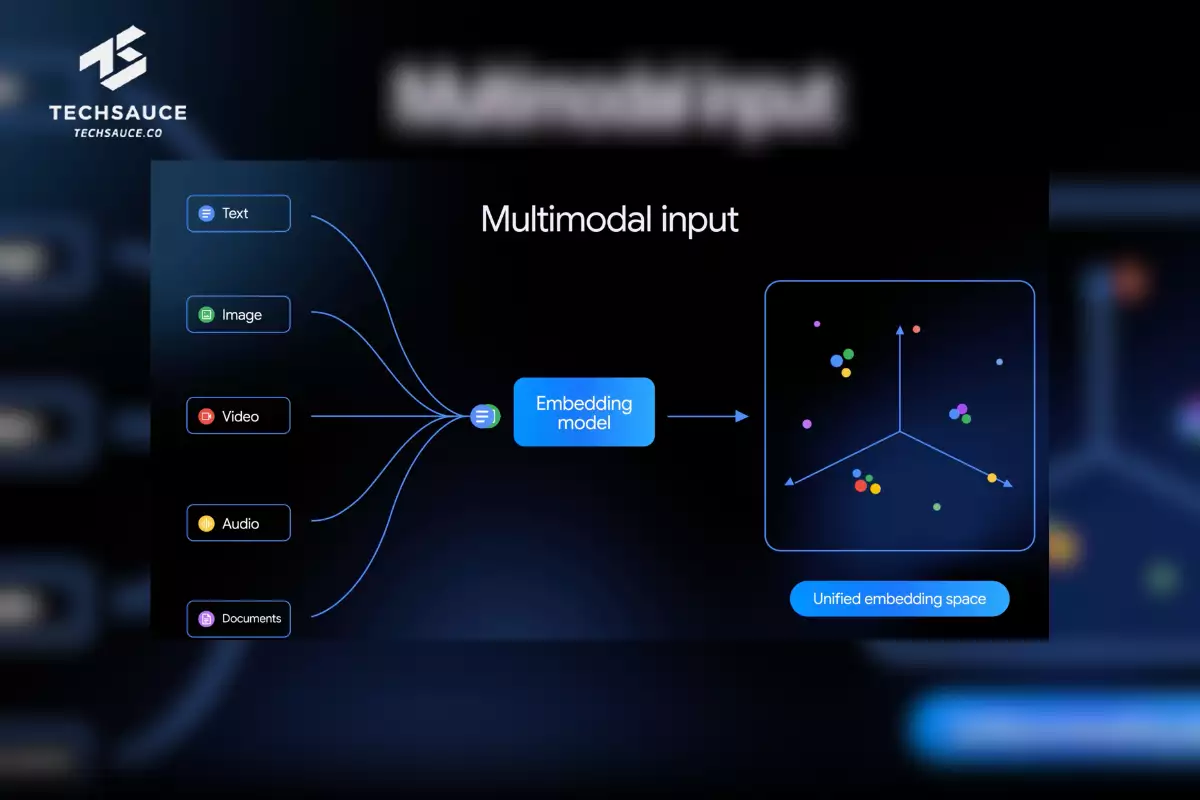
จุดเด่นที่สุดของ Gemini Embedding 2 คือความสามารถในการแปลงข้อมูล 5 ประเภทลงใน Embedding Space เดียวกัน ได้แก่ ข้อความ (Text) ที่รองรับ Context สูงสุดถึง 8,192 Token, รูปภาพ (Images) สูงสุด 6 ภาพต่อ Request รองรับทั้ง PNG และ JPEG, วิดีโอ (Videos) ยาวสูงสุด 120 วินาที ในรูปแบบ MP4 และ MOV, เสียง (Audio) ที่ประมวลผลได้โดยตรงโดยไม่ต้องแปลงเป็นข้อความก่อน และเอกสาร (Documents) ในรูปแบบ PDF ยาวสูงสุด 6 หน้า
ยิ่งไปกว่านั้น โมเดลนี้ยังเข้าใจ "Interleaved Input" หรือการส่งข้อมูลหลาย Modality พร้อมกันในคำขอเดียว เช่น การส่งรูปภาพควบคู่กับข้อความในเวลาเดียวกัน ทำให้ AI สามารถจับความสัมพันธ์ที่ซับซ้อนระหว่างสื่อแต่ละประเภทได้อย่างแม่นยำยิ่งขึ้น พร้อมทั้งรองรับภาษามากกว่า 100 ภาษาทั่วโลก
Matryoshka Learning เพื่อความยืดหยุ่นในการพัฒนา
Gemini Embedding 2 นำเทคนิค Matryoshka Representation Learning (MRL) มาใช้ต่อยอดจากโมเดลรุ่นก่อน เทคนิคนี้ทำงานคล้ายกับตุ๊กตา Matryoshka ของรัสเซียที่ซ้อนกันอยู่ โดย "ซ้อน" ข้อมูลไว้ในมิติที่ต่างกัน ทำให้นักพัฒนาสามารถปรับขนาด Output Dimension ได้อย่างยืดหยุ่นตั้งแต่ 768, 1,536 ไปจนถึง 3,072 มิติ (ค่าเริ่มต้น) ตามความต้องการด้านประสิทธิภาพและต้นทุนการจัดเก็บข้อมูล โดย Google แนะนำให้ใช้ขนาด 3,072 มิติเพื่อคุณภาพสูงสุด
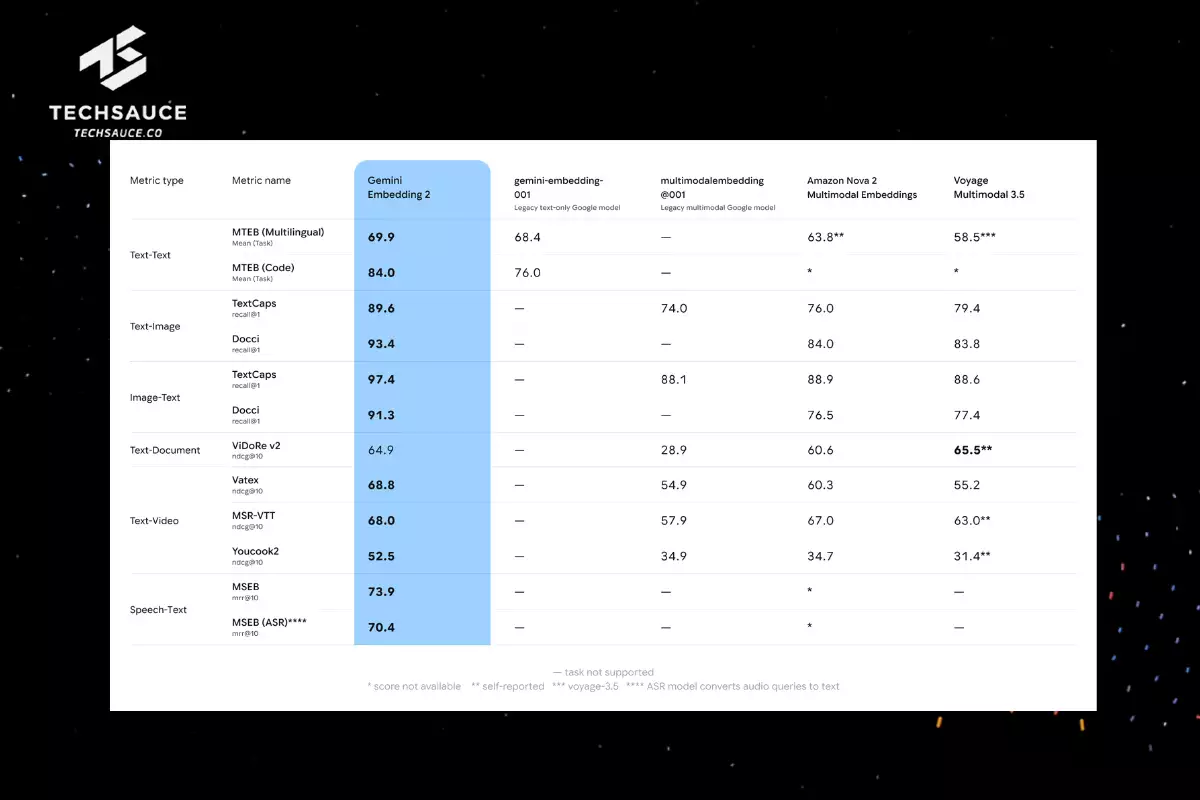
ด้านประสิทธิภาพ งานวิจัยที่ตีพิมพ์พร้อมการเปิดตัวชี้ว่า Gemini Embedding ทำคะแนน 68.32 บน MTEB (Multilingual) Leaderboard ซึ่งถือเป็นอันดับ 1 ด้วยคะแนนนำห่างจากโมเดลอันดับ 2 อย่าง multilingual-e5-large-instruct ถึง +5.09 คะแนน โดยเฉพาะในงาน Classification (+9.6), Clustering (+3.7) และ Retrieval (+9.0) ซึ่งสะท้อนให้เห็นถึงความได้เปรียบในเชิงความหมายและการเรียกคืนข้อมูลที่ชัดเจน สำหรับราคา เริ่มต้นที่ $0.20 ต่อ 1 ล้าน Token สำหรับข้อความ
กรณีศึกษาจากพาร์ตเนอร์ Early Access
ผลลัพธ์จากพาร์ตเนอร์ที่ได้ทดลองใช้งานก่อนเปิดตัวสาธารณะแสดงให้เห็นถึงประโยชน์ที่จับต้องได้ Sparkonomy แพลตฟอร์มด้าน Creator Economy รายงานว่า Latency ลดลงถึง 70% หลังจากตัด Intermediate LLM Inference Steps ออก พร้อมกับคะแนน Semantic Similarity ระหว่างข้อความและวิดีโอที่เพิ่มขึ้นเป็น 2 เท่า จาก 0.4 เป็น 0.8 ส่วน Mindlid แพลตฟอร์มด้าน Wellness ทำได้ดีขึ้น 20% ในด้าน Top-1 Recall จากการฝัง Conversational Memories ควบคู่กับข้อมูลเสียงและภาพ ขณะที่ Everlaw บริษัท Legal Tech นำไปใช้ค้นหาหลักฐานทางภาพในคดีความได้แม่นยำยิ่งขึ้นในฐานข้อมูลกฎหมายนับล้านรายการ
นักพัฒนาสามารถเริ่มทดลองใช้งาน Gemini Embedding 2 ได้ผ่าน Gemini API หรือ Vertex AI และยังรองรับ Integration กับ Ecosystem ยอดนิยมอย่าง LangChain, LlamaIndex, Haystack, Weaviate, QDrant และ ChromaDB ทำให้นำไปต่อยอดกับ Pipeline ที่มีอยู่ได้ทันทีโดยไม่ต้องสร้างระบบใหม่ทั้งหมด สำหรับผู้ที่อยากดูตัวอย่างจริง Google ยังเปิด Demo สาธิต Multimodal Semantic Search ให้ทดลองที่ findmemedia.lmm.ai อีกด้วย
ที่มา: Google Blog
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด

บอร์ดบีโอไอนำโดยคุณเอกนิติเยี่ยมชมโรงงานใหม่ ADI ที่ชลบุรี มูลค่ากว่า 19,000 ล้านบาท ตั้งเป้ามาตรฐาน LEED Platinum แห่งแรกของเครือข่ายทั่วโลก พร้อมขยายจ้างงานไทย 2,500 คน ตอกย้ำไทย...
 0
0

ผ่าแผน สทน. สู่ทศวรรษใหม่ ดันไทยเป็น 'Supply Chain' นิวเคลียร์โลก
ก้าวใหม่เทคโนโลยีนิวเคลียร์ไทย สทน. ฉลอง 20 ปี ชูวิสัยทัศน์ใช้ Science Diplomacy ดึงมหาอำนาจร่วมสร้าง SMR จิ๊กซอว์ชิ้นสำคัญสู่เป้าหมาย Net Zero...
0

กระทรวงการคลังและธนาคารแห่งประเทศไทย (ธปท.) แถลงความพร้อมอย่างเป็นทางการ ในการเป็นเจ้าภาพจัด 'การประชุมประจำปีสภาผู้ว่าการกองทุนการเงินระหว่างประเทศและกลุ่มธนาคารโลก ปี 2569' หรือ ...
0
